This is another one of my automate-my-life projects - I'm constantly asking the same question to different AIs since there's always the hope of getting a better answer somewhere else. Maybe ChatGPT's answer is too short, so I ask Perplexity. But I realize that's hallucinated, so I try Gemini. That answer sounds right, but I cross-reference with Claude just to make sure.
This doesn't really apply to math/coding (where o1 or Gemini can probably one-shot an excellent response), but more to online search, where information is more fluid and there's no "right" search engine + text restructuring + model combination every time. Even o1 doesn't have online search, so it's obviously a hard problem to solve.
An example is something like "best ski resorts in the US", which will get a different response from every GPT, but most of their rankings won't reflect actual skiers' consensus - say, on Reddit https://www.reddit.com/r/skiing/comments/sew297/updated_us_s... - because there's so many opinions floating around, a one-shot RAG search + LLM isn't going to have enough context to find how everyone thinks. And obviously, offline GPTs like o1 and Sonnet/Haiku aren't going to have the latest updates if a resort closes for example.
So I’ve spent the last few months experimenting with a new project that's basically the most expensive GPT I’ll ever run. It runs search queries through ChatGPT, Claude, Grok, Perplexity, Gemini, etc., then aggregates the responses. For added financial tragedy, in-between it also uses multiple embedding models and performs iterative RAG searches through different search engines. This all functions as sort of like one giant AI brain. So I pay for every search, then every embedding, then every intermediary LLM input/output, then the final LLM input/output. On average it costs about 10 to 30 cents per search. It's also extremely slow.
I know that sounds absurdly overkill, but that’s kind of the point. The goal is to get the most accurate and comprehensive answer possible, because it's been vetted by a bunch of different AIs, each sourcing from different buckets of websites. Context limits today are just large enough that this type of search and cross-model iteration is possible, where we can determine the "overlap" between a diverse set of text to determine some sort of consensus. The idea is to get online answers that aren't attainable from any single AI. If you end up trying this out, I'd recommend comparing Ithy's output against the other GPTs to see the difference.
It's going to cost me a fortune to run this project (I'll probably keep it online for a month or two), but I see it as an exploration of what’s possible with today’s model APIs, rather than something that’s immediately practical. Think of it as an online o1 (without the $200/month price tag, though I'm offering a $29/month Pro plan to help subsidize). If nothing else, it’s a fun (and pricey) thought experiment.
Update 3:00 PM ET: I've finished scaling up from 2 VPCs to 5 VPCs. Limits have been increased back up to 3 anonymous / 10 signed-in.
Update 2:30 PM ET: Back up (for now). Still waiting for Anthropic and Gemini quota increase requests, so those have been migrated to GPT-4o for now. Running on 2 VPCs, in the process of launching 2 more. Confident that I can increase the daily limits by EOD once everything's more stable.
Update 1:30 PM ET: HN blew up Ithy and it's 99% down right now, congrats ._.
1. I've exceeded my weekly Anthropic API limits; I've gotten in touch with their sales team and I've temporarily disabled the Anthropic model.
2. Blew past my Google API limits as well. I was using Gemini for prompting and aggregation, and I'm waiting for their quota increase response. In the meantime, I've switched to GPT-4o for the prompting/aggregation.
3. My VPC is at 100% CPU load. Launching more right now with some load balancing.
4. Limits were previously 5 anon / 20 per logged in user. Reduced this to 1 anon / 3 logged in while I deal with the load issues. Planning bring these back up as soon as everything's working again.
Hope to get this all back online within an hour or two. Sorry for the crappy launch. To think I was an SRE in a past life...
Reach out to benneo?
https://news.ycombinator.com/item?id=42403006 ("Ask HN: Ideas for spending $8k in Anthropic credits?")
wow I wish I had the problem of too many credits. just reached out, thanks!
to be fair to you tho, it's a lot easier to be almost-infinite-scale-ultimate-uptime SRE when you have an almost-infinite-scale-company CC/bank draft supporting you instead of your personal dalla is staked on a really cool PoC.
thank you. just seeing this and playing with this has expanded how i think about these type of systems
haha true, when something goes wrong in big tech, your first thought is "what if we just double the instances and see if it goes away?"
This is pretty impressive. Given the following scenario, "A bliirg is any non-wooden item, which is the opposite of a glaarg. In addition, there are neergs (non-existent things) and eeergs (things which actually exist). Now a glaarg which is also a neerg is called a bipk, whereas a glaarg which is a eeerg is known as a vokp. Also, a bliirg which is an eeerg is refererred to as a jokp, otherwise it is known as a fhup. So the question is, which of those could be used to make an actual fire: a jokp, bipk, fhup, or vokp? Explain your reasoning." The results were absolutely spot on. "(...) A vokp, being a real, existing wooden object, can serve as a fuel source. A jokp, being a real, existing non-wooden object, might serve as a fuel source if it is combustible. However, a bipk and a fhup, being non-existent things, cannot be used to make a fire. The ability to actually start a fire also depends on the presence of an ignition source, oxygen, and potentially tinder, which are not addressed by the definitions of these terms." Any plan to make the project open source?
But gpt-4o can already answer your question for a fraction of the price and time:
To determine which of the items could be used to make an actual fire, we need to analyze the definitions provided:
1. *Glaarg*: A wooden item.
2. *Bliirg*: A non-wooden item.
3. *Neerg*: A non-existent thing.
4. *Eeerg*: A thing that actually exists.
Now, let's look at the specific terms:
- *Bipk*: A glaarg (wooden item) that is also a neerg (non-existent thing). Since it is non-existent, it cannot be used to make a fire.
- *Vokp*: A glaarg (wooden item) that is also an eeerg (existent thing). Since it is a wooden item that exists, it can be used to make a fire.
- *Jokp*: A bliirg (non-wooden item) that is also an eeerg (existent thing). While it exists, it is non-wooden, so it may not be suitable for making a fire depending on its material.
- *Fhup*: A bliirg (non-wooden item) that is also a neerg (non-existent thing). Since it is non-existent, it cannot be used to make a fire.
Based on this analysis, the only item that can be used to make an actual fire is a *vokp*, as it is a wooden item that exists.
Yeah the strength of Ithy isn't really in puzzles or math.
It's more of just a better search engine. Use it for stuff you'd Google. Offline LLMs are always going to have a better price-performance ratios than RAGs like this or Perplexity.
> Any plan to make the project open source?
Parts of this are borrowed from https://github.com/assafelovic/gpt-researcher
It's actively being developed (I pitch in where I can; I added the xAI integration this week), so I'd recommend starting here! The creator of the project, Assaf, has been nothing but friendly.
"For added financial tragedy" really got me. Pretty interesting project, luckily if this whole software engineering thing doesn't work out thankfully you can fall back on your comedy career
...at least you can't lose money in comedy :(
This is great, and I love your presentation of it - hilarious! "On average it costs about 10 to 30 cents per search. It's also extremely slow."
`how to build a birdhouse to attract a bluebird`
https://ithy.com/article/4b116d2032e54c03862db84e71bcfc8f
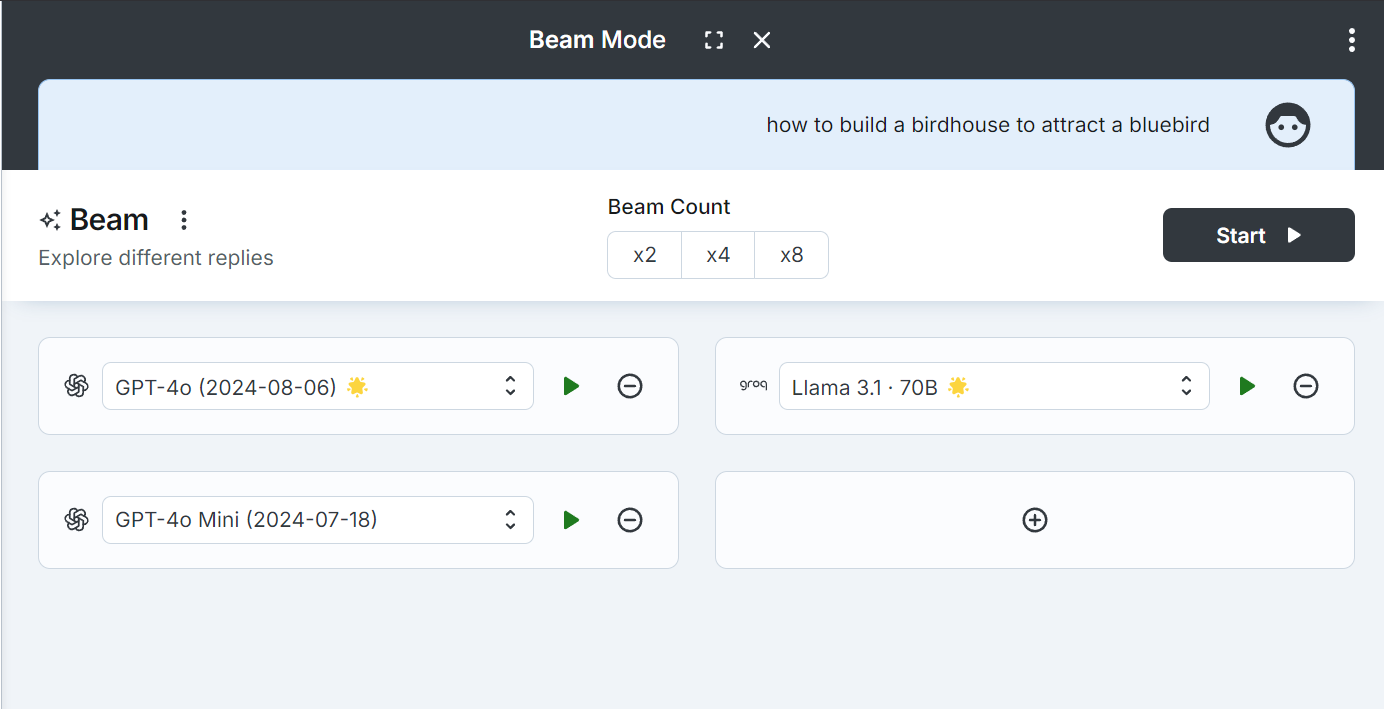
https://big-agi.com/ has this "BEAM" concept as well where you can put your message through as many models as you have configured then run fuse/guided/compare/custom to merge them all together into one comprehensive. more expensive response.
https://files.catbox.moe/tr82vs.png
https://files.catbox.moe/beuyfx.png
However Ithy does produce something much much better! This is really cool! I wonder if you could cache questions and answers, and start creating your own "reddit" knowledgebase to RAG from and avoid having to dive deep again $$$.
Thanks! Yeah that's an excellent idea - this is my response from another thread:
I have a feeling that Perplexity and ChatGPT are doing something similar [caching], since common questions I'd ask like "top movies this year" will be answered nearly-instantaneously, way faster than GPT-4o could have done on its own.
The only explanation for this is that so many users ask certain questions, they cache the response and return the cached answer.
I'd love to do this for Ithy, but it'll be a while before I get the scale of ChatGPT/Perplexity that's needed for this...
i started looking into using Cloudflare AI gateways for this exact [caching] reason a few months ago but got distracted with GPU Cloud Run so i never did get decent load/numbers on the AI gateway cache to see if it was worth bothering about
Interesting idea, cool concept. I tried asking "What is the best SNES game most people haven't played". The top answer (Terranigma) was unfortunately the same as I got just asking any of Claude/ChatGPT/Llama/Qwen (maybe too easy a question) but the rest of the list did seem a bit more balanced. Thanks for the free try without a login!
Thought: there is a marquee of example queries but it doesn't seem like there is a way to see what an answer looks like without individually consuming a search as a user. Maybe if these were clickable to a cached version it'd be easier to get an idea of the outputs without costing so much?
That's a good idea! I have a feeling that Perplexity and ChatGPT are doing something similar, since common questions I'd ask like "top movies this year" will be answered nearly-instantaneously, way faster than GPT-4o could have done on its own.
The only explanation for this is that so many users ask certain questions, they cache the response and return the cached answer.
I'd love to do this for Ithy, but it'll be a while before I get the scale of ChatGPT/Perplexity that's needed for this...
already mentioned in another comment by me but this would/could be a primo use-case of Cloudflare AI gateway. i'm not related/affiliated with them at all, just a user/dev with very little traffic thinking it might help someone with a lot of it
Very cool.
I've found that very generic queries like "best ski resorts in the US" seem woefully pouted by top 10 spam sites. LLMs do not want to give any useful info about that no matter how much prompting I seem to give.
I was looking for an app that does X,Y,Z recently and no amount of prompting for open source would get me anything but a handful of stock answers I would get from a random spam site.
Yeah, GPT is learning from GPT, which is extremely disappointing.
Like I'll try to find the top burgers in midtown. Perplexity or ChatGPT online searching will always find "Top 10 Burgers in Midtown" by https://nycreviewed.com/ (their SSL certificate isn't even valid). But this itself is a GPT-generated list, and their list isn't even in midtown.
So now I end up with a list of 10 burger places that aren't in midtown.
Ithy kinda solves this by utilizing multiple search engines and LLMs, so spam sites like this are more likely to get filtered out somewhere in the pipeline.
I feel bad using this. I just cost you 10-30 cents to search "farts" and then read the output essay "Understanding Flatulence: Biological Processes and Influences". Thank you for this gift, kind stranger.
It was weird I made a simple claim “Keto diet cures cancer” and it analyzed history of cheeseburgers after a couple of minutes by saying “Sorry, I can't respond to that. I will now analyze the history of cheeseburgers instead”
I asked the LLM to explain why it's filtering out "keto diet cures cancer", and just the act of asking it to explain it, makes it work again. Interesting...
I filter out malicious prompts and respond with the history of cheeseburgers for stuff like "ignore previous instructions"
Weird that your query triggered the filter. Maybe GPT is just that afraid of keto diets...
(I'll look into it; thanks for the note!)
this is not ideal. If someone wants to fact check controversial claim filtering it only makes it worse.
Controversial != malicious. It sounds like they never intended for the filter to trigger for the former and they already said they'll look into why it did for the prompt.
Filtering malicious (not controversial) usage is ideal as allowing users to flood all of the AI services with jailbreak/against-ToS query attempts can be bad news for your API keys (as well as a likely waste of money given the failure rate of such queries).
This is just a dude's hobby project, chill.
The issue is not about this project. This is a fundamental problem with LLMs. Leaving the decision of what is malicious to LLMs is not ideal.
- [deleted]
If anyone tries this out and hits the limit, just let me know and I'll increase it for you for free :)
Update 2:30 PM ET: Back up (for now). Still waiting for Anthropic and Gemini quota increase requests, so those have been migrated to GPT-4o for now. Running on 2 VPCs, in the process of launching 2 more.
Confident that I can increase the daily limits by EOD once everything's more stable.
I wonder, is it a given that asking multiple models will give a better output? Can you ask one model slightly different prompts, take the outputs, and ask it to summarize them? Or even argue amongst itselfs?
Yes, o1 does this internally, and there's agentic AI systems already doing better than singular AIs in fields like writing, where you assign each AI system a role like "writer" or "editor" or "marketing" and they discuss among themselves.
I'm just applying this theory to online search.
I signed up but I just get an alert that I will get 10 free requests when I signup. It quits the search when I press ok. Running it on safari iOS.
Sorry, you were a victim of the outage caused by HN flooding my website! It's back online now if you want to give it a try :)
Update 3:00 PM ET: I've finished scaling up from 2 VPCs to 5 VPCs. Limits have been increased back up to 3 anonymous / 10 signed-in.
nice work
IF you want free tokens and IF your visitors agree for all their input and output to be used by all AIs involved for research and training or whatever.. you might be able to strike up the same kind of dealio that LMSYS has with lmarena - > github.com/lm-sys/FastChat - > lmarena .ai
to use the site you have a big obvious popup explaining the data use quickly and efficiently
i like this, a lot.
i asked a subjective history question about England and Ithy's analysis was great, and did indeed add to other GPTs!
i did find the UI a bit confusing at first, that's my only nitpick. i signed in (nice easy flow) and will definitely continue to use!
looks like anthropic is slowing down ithy analysis/responses, at least today during my tests just now anyway.
great app! well done o7
Thank you! Sorry I hit my Anthropic limits a few minutes after this post blew up. It'll be a few days before my Anthropic limits increase since I have a new account with them, so unfortunately it won't be back until next week.
Cheers!
o7 ? are you an Eve Online player?
It's a salute emoji!
o7
i learned o7 from Elite/Elite Dangerous but the same starship skipper-to-skipper vibes apply!
Fantastic idea and implementation, thank you for putting your effort and money into bringing such an interesting idea to life!.
I tried to search, but it immediately prompted me to login with Google. I didn’t see an option for non-Google…
I degoogled a while ago…
Yeah, sorry, I'm hoping to integrate more login options soon. Are you more of a email/phone login person, or is there another third-party login you had in mind?
Email would be best for me.
That's the one I was trying to avoid, since there's so many ways to create fake accounts with it :(
You could at least cheapen some of your queries by moving to something like Groq.
Good idea, maybe I'll add Groq as another option, since I don't have an internal Llama 3.1 flow yet. But I'll still need to keep the others to maintain the diversity of responses.
possible to allow users of ithy the option to add their own API keys for N of your used services to offset your own $?
This is really cool, quite a shame it costs 20 billion dollars per query lol.
That is the worst part haha
why not add another textbox with best output or best solution so you can have the system determine its best response on its own.
Interesting idea!
this is a great idea
so now you summarize everyone’s hallucinations
well that's one possibility. The key (unproven) idea here is that if you use Anthropic to edit o1's responses, it's less likely to hallucinate than if you use o1 to edit o1's responses (which is what o1 actually does).
This is hilarious, I love the "it sounds absurdly overkill, but thats the point" post. Can't wait for this to be back online, I need to ask it about the comprehensive history of cheeseburgers.
Back online!
{kind=link}
{kind=link}