Similar CUDA core counts for most SKUs compared to last gen (except in the 5090 vs. 4090 comparison). Similar clock speeds compared to the 40-series.
The 5090 just has way more CUDA cores and uses proportionally more power compared to the 4090, when going by CUDA core comparisons and clock speed alone.
All of the "massive gains" were comparing DLSS and other optimization strategies to standard hardware rendering.
Something tells me Nvidia made next to no gains for this generation.
I started thinking today, when Nvidia seemingly keeps just magically increasing performance every two years, that they eventually have to "intel" themselves, where they haven't made any real architectural improvements in ~10 years and just suddenly power and thermals don't scale anymore and you have six generations of turds that all perform essentially the same, right?
it's possible, but idk why you would expect that. just to pick an arbitrary example since steve ran some recent tests, a 1080 ti is more or less equal to a 4060 in raster performance, but needs more than double the power and a much more die area to do it.
https://www.youtube.com/watch?v=ghT7G_9xyDU
we do see power requirements on the high end parts every generation, but that may be to maintain the desired SKU price points. there's clearly some major perf/watt improvements if you zoom out. idk how much is arch vs node, but they have plenty of room to dissipate more power over bigger dies if needed for the high end.
how many customers care about raster performance?
I do. Ray tracing, DLSS and especially frame-gen cause all sorts of weird visual artifacts. I'd rather just do without any of them.
I can’t exactly compare ray tracing performance when it didn’t exist at that time. or is this a joke about rendering games no longer being the primary use case for an nvidia gpu?
Nvidia is a very innovative company. They reinvent solutions to problems while others are trying to match their old solutions. As long as they can keep doing that, they will keep improving performance. They are not solely reliant on process node shrinks for performance uplifts like Intel was.
>They are not solely reliant on process node shrinks for performance uplifts like Intel was.
People who keep giving intel endless shit are probably very young and don't remember how innovative Intel was in the 90s and 00s. USB, PCI-Express, Thunderbolt, etc., all Intel inventions, plus involvement in Wifi and wireless telecom standards. They are guilty of anti competitive practices and complacency in the last years but their innovations weren't just node shrinks.
Those standards are plumbing to connect things to the CPU. The last major innovations that Intel had in the CPU itself were implementing CISC in RISC with programmable microcode in the Pentium and SMT in the Pentium 4. Everything else has been fairly incremental and they were reliant on their process node advantage to stay on top. There was Itanium too, but that effort was a disaster. It likely caused Intel to stop innovating and just rely on its now defunct process node advantage.
Intel’s strategy after it adopted EM64T (Intel’s NIH syndrome name for amd64) from AMD could be summarized as “increase realizable parallelism through more transistors and add more CISC instructions to do key work loads faster”. AVX512 was that strategy’s zenith and it was a disaster for them since they had to cut clock speeds when AVX-512 operations ran while AMD was able to implement them without any apparent loss in clock speed.
You might consider the more recent introduction of E cores to be an innovation, but that was a copy of ARM’s big.little concept. The motivation was not so much to save power as it was for ARM but to try to get more parallelism out of fewer transistors since their process advantage was gone and the AVX-512 fiasco had showed that they needed a new strategy to stay competitive. Unfortunately for Intel, it was not enough to keep them competitive.
Interestingly, leaks from Intel indicate that Intel had a new innovation in development called Royal Core, but Pat Gelsinger cancelled it last year before he “resigned”. The cancellation reportedly lead to Intel’s Oregon design team resigning.
> AVX512 was that strategy’s zenith and it was a disaster for them since they had to cut clock speeds when AVX-512 operations ran while AMD was able to implement them without any apparent loss in clock speed.
AMD up until zen 5 didn't have a full AVX-512 support so not exactly a fair comparison. Intel designs don't suffer from that issue AFAIU for couple of iterations already.
But I agree with you, I always thought and I still do that Intel has a very strong CPU core design but where AMD changed the name of the game IMHO is the LLC cache design. Hitting as much as ~twice lower LLC latency is insane. To hide this big of a difference in latency, Intel has to pack larger L2+LLC cache sizes.
Since LLC+CCX design scales so well AMD is also able to pack ~50% more cores per die, something Intel can't achieve even with the latest Granite Rapids design.
These two reasons let alone are big things for data center workloads so I really wonder how Intel is going to battle that.
AVX-512 is around a dozen different ISA extensions. AMD implemented the base AVX-512 and more with Zen 4. This was far more than Intel had implemented in skylake-X where their problems started. AMD added even more extensions with Zen 5, but they still do not have the full AVX-512 set of extensions implemented in a single CPU and neither does Intel. Intel never implemented every single AVX-512 extension in a single CPU:
https://en.wikipedia.org/wiki/AVX-512#CPUs_with_AVX-512
It also took either 4 or 6 years for Intel to fix its downclocking issues, depending on whether you count Rocket Lake as fixing a problem that started in enterprise CPUs, or require Sapphire Rapids to have been released to consider the problem fixed:
https://en.wikipedia.org/wiki/Advanced_Vector_Extensions#Dow...
Ok, fair enough, I didn't explain myself very well. What I more specifically meant is that AMD up until zen5 could not
in the same clock.(1) drive 2x AVX-512 computations (2) handle 2x AVX-512 memory loads + 1x AVX-512 memory storeThe latter makes a big impact wrt available memory BW per core, at least when it comes to the workloads whose data is readily available in L0 cache. Intel in these experiments is crushing AMD by a large factor simply because their memory controller design is able to sustain 2x64B loads + 1x64B stores in the same clock. E.g. 642 GB/s (Golden Cove) vs 334 GB/s (zen4) - this is a big difference and this is something that Intel had for ~10 years whereas AMD was able to solve this with zen5, basically only with the end of 2024.
Former one limits the theoretical FLOPS/core capabilities since single AVX-512 FMA operation in zen4 is implemented as two AVX2 uops occupying both FMA slots per clock. This is also big and, again, this is something where Intel had a lead up until zen5.
Wrt downclocking issues, they had a substantial impact with Skylake implementation but with Ice Lake this was a solved issue and this was in 2019. I'm cool with having ~97% of max freq budget available with heavy AVX-512 workloads.
OTOH AMD is also very thin with this sort of information and some experiments show that turbo boost clock frequency on zen4 lowers from one CCD to another CCD [1]. It seems like zen5 exhibits similar behavior [2].
So, although AMD is displaying continuous innovation for the past several years this is only because they had a lot to improve. Their pre-zen (2017) designs were basically crap and could not compete with Intel who OTOH had a very strong CPU design for decades.
I think that the biggest difference in CPU core design really is in the memory controller - this is something Intel will need to find an answer to since AMD matched all the Intel strengths that it was lacking with zen5.
[1] https://chipsandcheese.com/p/amds-zen-4-part-3-system-level-...
[2] https://chipsandcheese.com/p/amds-ryzen-9950x-zen-5-on-deskt...
System memory is not able to sustain such memory bandwidth so it seems like a moot point to me. Intel’s CPUs reportedly cannot sustain such memory bandwidth even when it is available:
https://www.ixpug.org/images/docs/ISC23/McCalpin_SPR_BW_limi...
Not sure I understood you. You think that AVX-512 workload and store-load BW are irrelevant because main system memory (RAM) cannot keep up with the speed of CPU caches?
I think the benefits of more AVX-512 stores and loads per cycle is limited because the CPU is bottlenecked internally as shown in the slides from TACC I linked:
https://www.ixpug.org/images/docs/ISC23/McCalpin_SPR_BW_limi...
Your 642 GB/s figure should be for a single Golden Cove core, and it should only take 3 Golden Cove cores to saturate the 1.6 TB/sec HBM2e in Xeon Max, yet internal bottlenecks prevented 56 Golden Cove cores from reaching the 642 GB/s read bandwidth you predicted a single core could reach when measured. Peak read bandwidth was 590 GB/sec when all 56 cores were reading.
According to the slides, peak read bandwidth for a single Golden Cove core in the sapphire rapids CPU that they tested is theoretically 23.6GB/sec and was measured at 22GB/sec.
Chips and Cheese did read bandwidth measurements on a non-HBM2e version of sapphire rapids:
https://chipsandcheese.com/p/a-peek-at-sapphire-rapids
They do not give an exact figure for multithreaded L3 cache bandwidth, but looking at their chart, it is around what TACC measured for HBM2e. For single threaded reads, it is about 32 GB/sec from L3 cache, which is not much better than it was for reads from HBM2e and is presumably the effect of lower latencies for L3 cache. The Chips and Cheese chart also shows that Sapphire Rapids reaches around 450 GB/sec single threaded read bandwidth for L1 cache. That is also significantly below your 642 GB/sec prediction.
The 450 GB/sec bandwidth out of L1 cache is likely a side effect of the low latency L1 accesses, which is the real purpose of L1 cache. Reaching that level of bandwidth out of L1 cache is not likely to be very useful, since bandwidth limited operations will operate on far bigger amounts of memory than fit in cache, especially L1 cache. When L1 cache bandwidth does count, the speed boost will last a maximum of about 180ns, which is negligible.
What bandwidth CPU cores should be able to get based on loads/stores per clock and what bandwidth they actually get are rarely ever in agreement. The difference is often called the Von Neumann bottleneck.
> Your 642 GB/s figure should be for a single Golden Cove core
Correct.
> That is also significantly below your 642 GB/sec prediction.
Not exactly the prediction. It's an extract from one of the Chips and Cheese articles. In particular, the one that covers the architectural details of Golden Cove core and not Sapphire Rapids core. See https://chipsandcheese.com/p/popping-the-hood-on-golden-cove
From that article, their experiment shows that Golden Cove core was able to sustain 642 GB/s in L1 cache with AVX-512.
> They do not give an exact figure for multithreaded L3 cache bandwidth,
They quite literally do - it's in the graph in "Multi-threaded Bandwidth" section. 32-core Xeon Platinum 8480 instance was able to sustain 534 GB/s from L3 cache.
> The Chips and Cheese chart also shows that Sapphire Rapids reaches around 450 GB/sec single threaded read bandwidth for L1 cache.
If you look closely into my comment you're referring to you will see that I explicitly referred to Golden Cove core and not to the Sapphire Rapids core. I am not being pedantic here but they're actually different things.
And yes, Sapphire Rapids reach 450 GB/s in L1 for AVX-512 workloads. But SPR core is also clocked @3.8Ghz which is much much less than what the Golden Cove core is clocked at - @5.2GHz. And this is where the difference of ~200 GB/s comes from.
> Reaching that level of bandwidth out of L1 cache is not likely to be very useful, since bandwidth limited operations will operate on far bigger amounts of memory than fit in cache, especially L1 cache
With that said, both Intel and AMD are limited by the system memory bandwidth and both are somewhere in the range of ~100ns per memory access. The actual BW value will depend on the number of cores per chip but the BW is roughly the same since it heavily depends on the DDR interface and speed.
Does that mean that both Intel and AMD are basically of the same compute capabilities for workloads that do not fit into CPU cache?
And AMD just spent 7 years of their engineering efforts to implement what now looks like a superior CPU cache design and vectorized (SIMD) execution capabilities only to be applicable very few (mostly unimportant in grand scheme of things) workloads that actually fit into the CPU cache?
I'm not sure I follow this reasoning but if true then AMD and Intel have nothing to compete against each other since by the logic of CPU caches being limited in applicability, their designs are equally good for the most $$$ workloads.
It is not that the entire working set has to fit within SRAM. Kernels that reuse portions of their inputs several times, such as matmul, can be compute bound and there AMD's AVX-512 shines.
Parent comment I am responding to is arguing that CPU caches are not that relevant because the CPU for bigger workloads is anyways bottlenecked by the system memory BW. And thus, AVX-512 is irrelevant because it can only provide compute boost for a very small fraction of time (reciprocal to the size of the L1 cache).
I am in disagreement with that obviously.
Your description of what I told you is nothing like what I wrote at all. Also, the guy here is telling you that AVX-512 shines on compute bound workloads, which is effectively what I have been saying. Try going back and rereading everything.
Sorry, that's exactly what you said and the reason why we are having this discussion in the first place. I am guilty of being too patient with trolls such as yourself. If you're not a troll, then you're clueless or detached from reality. You're just spitting a bunch of incoherent nonsense and moving goalposts when lacking an argument.
I am a well known OSS developer with hundreds of commits in OpenZFS and many commits in other projects like Gentoo and the Linux kernel. You keep misreading what I wrote and insist that I said something I did not. The issue is your lack of understanding, not mine.
I said that supporting 2 AVX-512 reads per cycle instead of 1 AVX-512 read per cycle does not actually matter very much for performance. You decided that means I said that AVX-512 does not matter. These are very different things.
If you try to use 2 AVX-512 reads per cycle for some workload (e.g. checksumming, GEMV, memcpy, etcetera), then you are going to be memory bandwidth bound such that the code will run no faster than if it did 1 AVX-512 read per cycle. I have written SIMD accelerated code for CPUs and the CPU being able to issue 2 SIMD reads per cycle would make zero difference for performance in all cases where I would want to use it. The only way 2 AVX-512 reads per cycle would be useful would be if system memory could keep up, but it cannot.
I agree server CPUs are underprovisioned for memBW. Each core's share is 2-4 GB/s, whereas each could easily drive 10 GB/s (Intel) or 20+ (AMD).
I also agree "some" (for example low-arithmetic-intensity) workloads will not benefit from a second L1 read port.
But surely there are other workloads, right? If I want to issue one FMA per cycle, streaming from two arrays, doesn't that require maintaining two loads per cycle?
In an ideal situation where your arrays both fit in L1 cache and are in L1 cache, yes. However, in typical real world situations, you will not have them fit in L1 cache and then what will happen after the reads are issued will look like this:
As we are doing FMA on arrays, this is presumably part of a tight loop. During the first few loop iterations, the CPU core’s memory prefetcher will figure out that you have two linear access patterns and that your code is likely to request the next parts of both arrays. The memory prefetcher will then begin issuing loads before your code does and when the CPU issues a load that has already been issued by the prefetcher, it will begin waiting on the result as if it had issued the load. Internally, the CPU is pipelined, so if it can only issue 1 load per cycle, and there are two loads to be issued, it does not wait for the first load to finish and instead issues the second load on the next cycle. The second load will also begin waiting on a load that was done early by the prefetcher. It does not really matter whether you are issuing the AVX-512 loads in 1 cycle or 2 cycles, because the issue of the loads will occur in the time while we are already waiting for the loads to finish thanks to the prefetcher beginning the loads early.* Some time passes * Load 1 finishes * Some time passes * Load 2 finishes * FMA executesThere is an inherent assumption in this that the loads will finish serially rather than in parallel, and it would seem reasonable to think that the loads will finish in parallel. However, in reality, the loads will finish serially. This is because the hardware is serial. On the 9800X3D, the physical lines connecting the memory to the CPU can only send 128-bits at a time (well, 128-bits that matter for this reasoning; we are ignoring things like transparent ECC that are not relevant for our reasoning). An AVX-512 load needs to wait for 4x 128-bits to be sent over those lines. The result is that even if you issue two AVX-512 reads in a single cycle, one will always finish first and you will still need to wait for the second one.
I realize I did not address L2 cache and L3 cache, but much like system RAM, neither of those will keep up with 2 AVX-512 loads per cycle (or 1 for that matter), so what will happen when things are in L2 or L3 cache will be similar to what happens when loads come from system memory although with less time spent waiting.
It could be that you will end up with the loop finishing a few cycles faster with the 2 AVX-512 read per cycle version (because it could make the memory prefetcher realize the linear access pattern a few cycles faster), but if your loop takes 1 billion cycles to execute, you are not going to notice a savings of a few cycles, which is why I think being able to issue 2 AVX-512 loads instead of 1 in a single cycle does not matter very much.
Does my explanation make sense?
OK, we agree that L1-resident workloads see a benefit. I also agree with your analysis if the loads actually come from memory.
Let's look at a more interesting case. We have a dataset bigger than L3. We touch a small part of it with one kernel. That is now in L1. Next we do a second kernel where each of the loads of this part are L1 hits. With two L1 ports, the latter is now twice as fast.
Even better, we can work on larger parts of the data such that it still fits in L2. Now, we're going to do the above for each L1-sized piece of the L2. Sure, the initial load from L2 isn't happening as fast as 2x64 bytes per cycle. But still, there are many L1 hits and I'm measuring effective FMA throughput that is _50 times_ as high as the memory bandwidth would allow when only streaming from memory. It's simply a matter of arranging for reuse to be possible, which admittedly does not work with single-pass algorithms like a checksum.
Do you find this reasoning convincing?
The purpose of L1 cache is to avoid long round trips to memory. What you describe is L1 cache doing what it is intended to do. Unfortunately, I do not have your code, so it is not clear to me that it benefits from doing 2 AVX-512 loads per cycle.
I am also not sure what CPU this is. On recent AMD processors at the very least, it should be impossible to get FMA throughput that is 50 times higher from L1 cache bandwidth than system memory bandwidth. On the Ryzen 7 9800X3D for example, a single core is limited to about 64GB/sec. 50 times more would be 3.2TB/sec, which is ~5 times faster than possible to load from L1 cache even with 2 AVX-512 loads per cycle.
I wonder if you are describing some sort of GEMM routine, which is a place where 50 times more FMA throughput is possible if you do things in a clever way. GEMM is somewhat weird, since without copying to force things into L1 cache, it does not run at full speed, and memory bandwidth from RAM is always below peak memory bandwidth, even without the memcpy() trick to force things into L1 cache. That excludes the case where you stuff GEMV in GEMM, where it does become memory bandwidth bound.
The code is unfortunately not (yet) open source. The CPU with 50x is an SKX Gold, and it is similar for Zen4. I compute this ratio as #FMA * 4 / total system memory bandwidth. We are indeed not fully memBW bound :)
I'd be curious if you measured 50x on a single core implementation or is the algorithm distributed to multiple cores?
I ask because you say that the results are similar to Zen4 so this would sorta imply that you run and measure single-core implementation? Intel in multi-core load-store looses a lot of bandwidth when compared to Zen3/4/5 since there's a lot of contention going on due to Intel cache architecture.
- [deleted]
> They quite literally do - it's in the graph in "Multi-threaded Bandwidth" section. 32-core Xeon Platinum 8480 instance was able to sustain 534 GB/s from L3 cache.
They do not. The chip has 105MB L3 cache and they tested on 128MB of memory. This exceeds the size of L3 cache and thus, it is not a proper test of L3 cache.
> If you look closely into my comment you're referring to you will see that I explicitly referred to Golden Cove core and not to the Sapphire Rapids core. I am not being pedantic here but they're actually different things.
Sapphire Rapids uses Golden Cove cores.
> And yes, Sapphire Rapids reach 450 GB/s in L1 for AVX-512 workloads. But SPR core is also clocked @3.8Ghz which is much much less than what the Golden Cove core is clocked at - @5.2GHz. And this is where the difference of ~200 GB/s comes from.
This would explain the discrepancy between your calculation and the L1 cache performance, although being able to get that level of bandwidth only out of L1 cache is not very useful for the reasons I stated.
> I'm not sure I follow this reasoning but if true then AMD and Intel have nothing to compete against each other since by the logic of CPU caches being limited in applicability, their designs are equally good for the most $$$ workloads.
You seem to view CPU performance as being determined by memory bandwidth rather than computational ability. Upon being correctly told L1 cache memory bandwidth does not matter since the bottleneck is system memory, you assume that only system memory performance matters. That would be true if the primary workload of CPUs were memory bandwidth bound workloads, but it is not since the primary workloads of CPUs is compute bound workloads. Thus, how fast CPUs read from memory does not really matter for CPU workloads.
The purpose of a CPU’s cache is to reduce the von Neumann bottleneck by cutting memory access latency. That way the CPU core spends less time waiting before it can use the data and it can move on to a subsequent calculation. How much memory throughput CPUs get from L1 cache is irrelevant to CPU performance outside of exceptional circumstances. There are exceptional circumstances where cache memory bandwidth matters, but they are truly exceptional since any importan workload where memory bandwidth matters is offloaded to a GPU because a GPU often has 1 to 2 orders of magnitude more memory bandwidth than a CPU.
That said, it would be awesome if the performance of a part could be determined by a simple synthetic benchmark such as memory bandwidth, but that is almost never the case in practice.
> They do not. The chip has 105MB L3 cache and they tested on 128MB of memory. This exceeds the size of L3 cache and thus, it is not a proper test of L3 cache.
First, you claimed that there was no L3 BW test. Now, I am not even sure if you're trolling me or lacking knowledge or what at this point?
Please do tell what you consider a "proper test of L3 cache"? And why do you consider their test invalid?
I am curious because triggering 32 physical core threads to run over 32 independent chunks of data (totaling 3G and not 128M) seems like a pretty valid read BW experiment to me.
> Sapphire Rapids uses Golden Cove cores.
Right, but you missed the part that former is configured for the server market and the latter for the client market. Two different things, two different chips, different memory controllers if you wish. That's why you cannot compare one to each other directly without caveats.
Chips and Cheese are actually guilty of doing that but it's because they're lacking more HW to compare against. So some figures that you find in their articles can be misleading if you are not aware of it.
> You seem to view CPU performance as being determined by memory bandwidth rather than computational ability.
But that's what you said trying to refute the fact why Intel was in a lead over AMD up until zen5? You're claiming that AVX-512 workloads and load-store BW are largely irrelevant because CPUs are anyway bottlenecked by the system memory bandwidth.
> That would be true if the primary workload of CPUs were memory bandwidth bound workloads, but it is not since the primary workloads of CPUs is compute bound workloads. Thus, how fast CPUs read from memory does not really matter for CPU workloads.
I am all ears to hear what datacenter workloads you have in mind that are CPU-bound?
Any workload besides the most simplest one is at some point bound by the memory BW.
> The purpose of a CPU’s cache is to reduce the von Neumann bottleneck by cutting memory access latency.
> That way the CPU core spends less time waiting before it can use the data and it can move on to a subsequent calculation.
> How much memory throughput CPUs get from L1 cache is irrelevant to CPU performance outside of exceptional circumstances.
You're contradicting your own claims by saying that cache is there to hide (cut) the latency but then you continue to say that this is irrelevant. Not sure what else to say here.
> but they are truly exceptional since any importan workload where memory bandwidth matters is offloaded to a GPU because a GPU often has 1 to 2 orders of magnitude more memory bandwidth than a CPU.
99% of the datacenter machines are not attached to the GPU. Does that mean that 99% of datacenter workloads are not "truly exceptional" for whatever the definition of that formulation and they are therefore mostly CPU bound?
Or do you think they might be memory-bound but are missing out for not being offloaded to the GPU?
> First, you claimed that there was no L3 BW test.
I claimed that they did not provide figures for L3 cache bandwidth. They did not.
> Now, I am not even sure if you're trolling me or lacking knowledge or what at this point?
You should be grateful that a professional is taking time out of his day to explain things that you do not understand.
> Please do tell what you consider a "proper test of L3 cache"? And why do you consider their test invalid?
You cannot measure L3 cache performance by measuring the bandwidth on a region of memory larger than the L3 cache. What they did is a partially cached test and it does not necessarily reflect the true L3 cache performance.
> I am curious because triggering 32 physical core threads to run over 32 independent chunks of data (totaling 3G and not 128M) seems like a pretty valid read BW experiment to me.
You just described a generic memory bandwidth test that does not test L3 cache bandwidth at all. Chips and Cheese’s graphs show performance at different amounts of memory to show the performance of the memory hierarchy. When they exceed the amount of cache at a certain level, the performance transitions to different level. They did benchmarks on different amounts of memory to get the points in their graph and connected them to get a curve.
> Right, but you missed the part that former is configured for the server market and the latter for the client market. Two different things, two different chips, different memory controllers if you wish. That's why you cannot compare one to each other directly without caveats.
The Xeon Max chips with its HBM2e memory is the one place where 2 AVX-512 loads per cycle could be expected to be useful, but due to internal bottlenecks they are not.
Also, for what it is worth, Intel treats AVX-512 as a server only feature these days, so if you are talking about Intel CPUs and AVX-512, you are talking about servers.
> But that's what you said trying to refute the fact why Intel was in a lead over AMD up until zen5? You're claiming that AVX-512 workloads and load-store BW are largely irrelevant because CPUs are anyway bottlenecked by the system memory bandwidth.
I never claimed AVX-512 workloads were irrelevant. I claimed doing more than 1 load per cycle on AVX-512 was not very useful for performance.
Intel losing its lead in the desktop space to AMD is due to entirely different reasons than how many AVX-512 loads per cycle AMD hardware can do. This is obvious when you consider that most desktop workloads do not touch AVX-512. Certainly, no desktop workloads on Intel CPUs touch AVX-512 these days because Intel no longer ships AVX-512 support on desktop CPUs.
To be clear, when you can use AVX-512, it is useful, but the ability to do 2 loads per cycle does not add to the usefulness very much.
> I am all ears to hear what datacenter workloads you have in mind that are CPU-bound?
This is not a well formed question. See my remarks further down in this reply where I address your fabricated 99% figure for the reason why.
> Any workload besides the most simplest one is at some point bound by the memory BW.
Simple workloads are bottlenecked by memory bandwidth (e.g. BLAS levels 1 and 2). Complex workloads are bottlenecked by compute (e.g. BLAS level 3). A compiler for example is compute bound, not memory bound.
> You're contradicting your own claims by saying that cache is there to hide (cut) the latency but then you continue to say that this is irrelevant. Not sure what else to say here.
There is no contradiction. The cache is there to hide latency. The TACC explanation of how queuing theory applies to CPUs makes it very obvious that memory bandwidth is inversely proportional to memory access times, which is why the cache has more memory bandwidth than system RAM. It is a side effect of the actual purpose, which is to reduce memory latency. That is an attempt to reduce the von Neumann bottleneck.
To give a concrete example, consider linked lists. Traversing a linked list requires walking random memory locations. You have a pointer to the first item on the list. You cannot go to the second item without reading the first. This is really slow. If the list is frequently accessed to be in cache, then the cache will hide the access times and make this faster.
> 99% of the datacenter machines are not attached to the GPU. Does that mean that 99% of datacenter workloads are not "truly exceptional" for whatever the definition of that formulation and they are therefore mostly CPU bound?
99% is a number you fabricated. Asking if something is CPU bound only makes sense when you have a GPU or some other accelerator attached to the CPU that needs to wait on commands from the CPU. When there is no such thing, asking if it is CPU bound is nonsensical. People instead discuss being compute bound, memory bandwidth bound or IO bound. Technically, there are three ways to be IO bound, which are memory, storage and network. Since I was already discussing memory bandwidth bound work loads, my inclusion of IO bound as a category refers to the other two subcategories.
By the way, while memory bandwidth bound workloads are better run on GPUs than CPUs, that does not mean all workloads on GPUs are memory bandwidth bound. Compute bound workloads with minimal branching are better done on GPUs than CPUs too.
You're going a long way not to address reasonably simple questions I had. You're very combative for no obvious reason - I think I had my arguments laid out in the most objective form I could but unfortunately you seem to be very triggered by those especially by the logical concerns I raised. You are in the wrong here simply because you're assuming that all the experience you have is representative of all other experience people have in this industry. There are much larger challenges than designing a filesystem, you know. No need to be so vain.
Not only you're ending up being very disrespectful but you're also pulling out the appeal to authority argument. Also something Brendan Gregg did on me here at HN meaning that no experience can substitute the amount of ego in some guys.
FWIW you can be let assured that you can't match my experience but that's not the argument I would ever pull off. I like to be proved wrong. This is a way I learn new things. BTW I designed my first CPU 15 years ago but during the career I learned to put my ego aside, discuss objectively, think critically and learn on my own reasoning mistakes from other people. Many of these points you are obviously lacking so this is a waste of time for me - I see no way to drive this discussion further but thanks anyway.
e cores are more like atom - intel owes no credit to arm.
Intel's E cores are literally derived from the Atom product line. But the practice of including a heterogeneous mix of CPU core types was developed and proven and made mainstream within the ARM ecosystem before being hastily adopted by Intel as an act of desperation (dragging Microsoft along for the ride).
There is one major 4 letter difference - TSMC. Nvidia will get tech process improvements until TSMC can't deliver, and if that happens we have way bigger problems... because Apple will get mad they can't reinvent iPhone again... and will have to make it fun and relatable instead by making it cheaper and plastic again.
As long as TSMC keeps improving die size it will keep getting incremental improvements. These power/thermal improvements are not really that much up to nvidia.
The intel problem was that their foundries couldn't improve the die size while the other foundries kept improving theirs. But technically nvidia can switch foundry if another one proves better than TSMC even though that doesn't seem likely (at least without a major breakthrough not capitalized by ASML).
I mean it's like 1/6 of their revenue now and will probably keep sliding in importance over the datacenter. No real competition no matter how we would wish. AMD seems to have given up on the high end and Intel is focusing on the low end (for now, unless they cancel it in the next year or so).
From what I've seen they've targeted the low end in price, but solid mid-range in performance. It's hard to know if that's a strategy to get started (likely) with price increases down the road or they're really that competitive.
Intel's iGPUs were low end. Battlemage looks firmly mid-range at the moment with between 4060/4070 performance in a lot of cases.
They already predicted this hence DLSS and other AI magic.
Huh? Nvidia does three things well: - They support the software ecosystem - Cuda isn't a moat, but it's certainly an attractive target. - They closely follow fab leaders (and tend not to screw up much on logistics). - They do introduce moderate improvements in hardware design/features, not a lot of silly ones, and tending to buttress their effort to make Cuda a moat.
None of this is magic. None of it is even particularly hard. There's no reason for any of it to get stuck. (Intel's problem was letting the beancounters delay EUV - no reason to expect there to be a similar mis-step from Nvidia.)
> All of the "massive gains" were comparing DLSS and other optimization strategies to standard hardware rendering.
> Something tells me Nvidia made next to no gains for this generation.
Sounds to me like they made "massive gains". In the end, what matters to gamers is
1. Do my games look good? 2. Do my games run well?
If I can go from 45 FPS to 120 FPS and the quality is still there, I don't care if it's because of frame generation and neural upscaling and so on. I'm not going to be upset that it's not lovingly rasterized pixel by pixel if I'm getting the same results (or better, in some cases) from DLSS.
To say that Nvidia made no gains this generation makes no sense when they've apparently figured out how to deliver better results to users for less money.
Rasterizing results in better graphics quality than DLSS if compute is not a limiting factor. They are trying to do an apples to oranges comparison by comparing the FPS of standard rendering to upscaled images.
I use DLSS type tech, but you lose a lot of fine details with it. Far away text looks blurry, textures aren’t as rich, and lines between individual models lose their sharpness.
Also, if you’re spending $2000 for a toy you are allowed to have high standards.
> if compute is not a limiting factor.
If we're moving towards real time tracing compute is going to always be a limitting factor, as it was in the days of pre rendering. Granted currently raster techniques can simulate ray trace pretty well in many scenarios and looks much better in motion, IMO that's more limitation of real time ray trace. There's a bunch of image quality improvements beyond raster to be gained if enough compute is throw at ray tracing, i think a lot of dlss / frame generation goal is basically to offload more cpu to generate higher IQ hero frames while filling in blanks.
> Rasterizing results in better graphics quality than DLSS if compute is not a limiting factor.
Sure, but compute is a limiting factor.
I was demonstrating the Apples to Oranges comparison. If they were both free no one would pick DLSS. It shows Rasterizing is preferable. So comparing Rasterizing performance to DLSS performance is dishonest.
Except that if rendering was magically free... why not just pathtrace everything?
DLSS might not be as good as pure unlimited pathtracing, but for a given budget it might be better than rasterization alone.
I agree it’s worth the trade off. I use upscalers a lot.
I’m saying that it’s different enough that you shouldn’t compare the two.
DLSS 4 uses a completely new model with twice as many parameters and seems to be a big improvement.
I hope so, because it looks like 8k traditional rendering won’t be an option for this decade.
Will NEXT decade be possible?
8k traditional rendering at 144Hz is a lot of pixels. We are seeing a 25%/3 years improvement cycle on traditional rendering at this point, and we need about 8x improvement in current performance to get there.
2040 is definitely possible, but certainly not guaranteed.
So at 2040 we might be able to render at top 2025 display specs.
Makes you wonder how far ahead displays will be in 2040. I can imagine display prices falling in price and increasing in quality to the point where many homes just have displays paneled around the walls instead of paint.
You won't be using display panels / monitors at all. It will be the Apple Vision Pro 14 Pro Max. A tiny thing you touch on your head and you view the rasterized world at 12k 120fps all around you.
Why is that an issue? Do you have an 8k monitor?
Even 4k monitors are relatively rare and most monitors today are still 1080p, 60 Hz. Yes, you don't need a 5090 to play games on that, but 5090 is a very niche product, while x060 cards are the overwhelming majority. 8k rendering is needed just for the 5 or 6 people that wants it.
there aren't many 8k monitors. I would rather have 300fps 4k
What is the draw to 300fps?
240Hz or higher monitors. 4K is enough for spatial resolution then it is better to increase temporal resolution. 4K at 240Hz stops looking like looking at a screen and starts looking out a window.
4K alone is not enough to define spatial resolution. You also need take into account physical dimensions. DPI is a better way to describe spatial resolution. Anything better than 200 DPI is good, better than 300 is awesome.
Unfortunately, there are no 4K displays with 200+ DPI on the market. If you want high DPI you either need pick glossy 5k@27" or go to 6k/8k.
of course "normal viewing distances" is always implied when talking about monitors. And if you REALLY want to get pedantic you need to talk about pixels per degree. The human eye can see about 60. according to the very handy site https://qasimk.io/screen-ppd/
a 27" 1080p screen has 37ppd at 2 feet.
a 42" 4k screen has 51ppd at 2 feet.
a 27" 8k screen has 147ppd at 2 feet which is just absurd.
You have to get to 6 inches for the PPD to be 61
> The human eye can see about 60
I cannot brag with sharp eyesight, but I can definitely tell difference between 4k@27" at 60cm = 73PPD and 5k@27" at 60cm = 97PPD. Text is much crisper on the latter.
I've also compared Dell 8k to 6k. There is a still a difference, but it is not that big.
"Much crisper"
You must have exceptional eyesight.
But a 42" 8K screen should have around ~100 ppd, which is really nice but not unnecessarily detailed.
I know I'll be gunning for the 42" 8K's whenever they actually reach a decent market price. Sigh, still too many years away.
> Unfortunately, there are no 4K displays with 200+ DPI on the market.
There are 4k 24" monitors (almost 200 DPI) and 4k 18.5" portable monitors (more than 200 DPI) you can buy nowadays
4k 24" monitors used to exist, but they've disappeared from the market and now the choices are either 27+" or laptop panels.
Why did they stop making those? When I went to 4K, I wanted to get a 24” monitor, but there were none.
VR, probably.
People with 240Hz or higher monitors. 4K is enough for spatial resolution then it is better to increase temporal resolution. 4K at 240Hz or higher looks like a window.
Well if they can reach 300fps at 4k then they can prove to everybody once and for all that their dick is bigger than everybody elses.
Cause it ain't about the gameplay or the usefulness. It's all about that big dick energy.
DLSS is becoming the standard rendering.
It's not. It's becoming the standard lazy choice for devs though.
Because if two frames are fake and only one frame is based off of real movements, then you've actually lost a fair bit of latency and will have noticably laggier controls.
Making better looking individual frames and benchmarks for worse gameplay experiences is an old tradition for these GPU makers.
DLSS 4 can actually generate 3 frames for ever 1 raster frame. When talking about frame rates well above 200 per second a few extra frames isn't that big of a deal unless you are a professional competitive gamer.
If you're buying a ridiculously expensive card for gaming you likely consider yourself a pro gamer. I don't think ai interpolation will be popular in the market
It really depends on how well it works.
If anyone thinks they are having laggier controls or losing latency off of single frames I have a bridge to sell them.
A game running at 60 fps averages around ~16 ms and good human reaction times don’t go much below 200ms.
Users who “notice” individual frames are usually noticing when a single frame is lagging for the length of several frames at the average rate. They aren’t noticing anything within the span of an average frame lifetime
you’re conflating reaction times and latency perception. these are not the same. humans can tell the difference down to 10ms, perhaps lower.
if you added 200ms latency to your mouse inputs, you’d throw your computer out the of the window pretty quickly.
yeah the "distance between frames" latency is just one overhead, everything adds up until you get real latency. 10ms for your wireless mouse then 3ms for your I/O hardware then 5ms for the game engine to process your input then 20ms for the graphics pipeline and so on and on.
30 FPS is 33.33333 MS 60 FPS is 16.66666 MS 90 FPS is 11.11111 MS 120 FPS is 8.333333 MS 140 FPS is 7.142857 MS 144 FPS is 6.944444 MS 180 FPS is 5.555555 MS 240 FPS is 4.166666 MS
Going from 30fps to 120fps is 25ms which is totally 100% noticeable even for layman (I actually tested this with my girlfriend, she could tell between 60fps and 120fps as well), but these generated frames from DLSS don't help with this latency _at all_.
Although the nVidia Reflex technology can help with this kind of latency in some situations in some non quantifiable ways.
Or at least defenestrate the mouse.
You think normal people can't tell? Go turn your monitor to 60hz in your video options and move your mouse in circles on your desktop, then go turn it back to 144hz or higher and move it around on your screen. If an average csgo or valorant player where to play with framegen while the real fps was about 60 and the rest of the frames where fake, it would be so completely obvious it's almost laughable. That said the 5090 can obviously run those games at 200+fps so they would just turn off any frame gen stuff. But a new/next gen twitch shooter will for sure expose it.
>If an average csgo or valorant player were to play with framegen while the real fps was about 60
That's just it isn't. This stuff isn't "only detectable by profession competitive gamers" like many are proposing. It's instantly noticeable to the average gamer.
What I think is going on here has to do with lousy game engine implementations: with modern graphics APIs you have to take extra steps beyond relying on the swapchain to avoid running ahead of the GPU for multiple frames. It's not obvious and and I suspect a lot of games aren't that good at managing that. If the CPU runs ahead, you have a massive multi-frame input-to-screen lag that changes a lot with monitor FPS. But it's not the extra frames themselves that make the difference. It's just correcting for poor code.
I can and do notice when a driver update or similar switches my monitor's refresh rate or mouse polling rate down. In the game I play most there is an inbuilt framerate test tool to see what the best framerate you can notice the difference between visually is. I and many other players are consistent (20 correct in a row) up to 720fps.
I'll take that bridge off your hands.
These are NVidia's financial results last quarter:
- Data Center: Third-quarter revenue was a record $30.8 billion
- Gaming and AI PC: Third-quarter Gaming revenue was $3.3 billion
If the gains are for only 10% of your customers, I would put this closer to the "next to no gains" rather than the "massive gains".
DLSS artifacts are pretty obvious to me. Modern games relying on temporal anti aliasing and raytracing tend to be blurry and flickery. I prefer last-gen games at this point, and would love a revival of “brute force” rasterization.
As long as you can still disable DLSS from the game menu, it is good enough for me. I don't care about fake frames, I disable fake frames.
If you're doing frame generation you're getting input lag. Frame generation from low framerates is pretty far from ideal.
Nvidia claims to have fixed this with Nvidia reflex 2. It will reposition the frame according to mouse movements.
Fake frames, fake gains
Are DLSS frames any more fake than the computed P or B frames?
Yes.
how so?
P and B frames are compressed versions of a reference image. Frames resulting from DLSS frame generation are predictions of what a reference image might look like even though one does not actually exist.
But MPEG is lossy compression which means they are kind of a just a guess. That is why MPEG uses motion vectors.
"MPEG uses motion vectors to efficiently compress video data by identifying and describing the movement of objects between frames, allowing the encoder to predict pixel values in the current frame based on information from previous frames, significantly reducing the amount of data needed to represent the video sequence"
There's a real difference between a lossy approximation as done by video compression, and the "just a guess" done by DLSS frame generation. Video encoders have the real frame to use as a target; when trying to minimize the artifacts introduced by compressing with reference to other frames and using motion vectors, the encoder is capable of assessing its own accuracy. DLSS fundamentally has less information when generating new frames, and that's why it introduces much worse motion artifacts.
it would be VERY interesting to have actual quantitative data on how many possible I video frames map to a specific P or B frame vs how many possible raster frames map to a given predicted DLSS frame. The lower this ration the more "accurate" the prediction is.
Compression and prediction are the same. Decompressing a lossy format is guessing how the original image might have looked like. The difference between fake frames and P and B frames is that the difference between prediction of fake frame and real frame is dependant on the user input.
... now I wonder ... Do DLSS models take mouse movements and keypresses into account?
The fps gains are directly because of the AI compute cores, I’d say that’s a net gain but not a the traditional sense preAI.
Kind of a half gain: smoothness improved, latency same or slightly worse.
By the way, I thought these AI things served to increase resolution, not frame rate. Why doesn't it work that way?
It's both. And it's going to continue until games are 100% and AI fever dream.
Right, I should have said "generate extra pixels in every frame, not interpolate whole frames". Doing the former also increases frame rate by reducing computation per pixel.
The human eye can't see more than 60 fps anyway
This is factually incorrect and I don't know where people get this idea from.
Just moving my mouse around, I can tell the difference between 60 and 144 fps when I move my pointer from my main monitor (144 hz) to my second monitor (60 hz).
Watching text scroll is noticeably smoother and with less eye tracking motion blur at 144 hz versus 60.
An object moving across my screen at 144 fps will travel fewer pixels per frame than 60 fps. This gain in motion fluidity is noticeable.
I remember when it was "the human eye can't see more than cinematic 24fps" sour grapes by people who couldn't get 60fps
Can definitely see more than 60, but it varies how much more you can see. For me it seems like diminishing returns beyond 144Hz.
Though some CRT emulation techniques require more than that to scale realistic 'flickering' effects.
You are right, but diminishing returns technically start around 60.
The human eyes are analog low pass filters, so beyond 60Hz is when things start to blur together, which is still desirable since that's what we see in real life. But there is a cutoff where even the blurring itself can no longer help increase fidelity. Also keep in mind that this benefit helps visuals even when the frame rate is beyond human response time.
This is laughably false and easy to disprove. Blurbusters did an analysis of this many years ago and we won't get "retina" refresh rates until we're at 1000Hz.
i can tell up to about 144Hz but struggle to really notice going from 144 to 240Hz. Even if you don't consciously notice the higher refresh rate it could still help for really fast paced games like competitive FPS if you can actually generate that many frames per second by reducing input latency and if you can actually respond fast enough.
Same with me. At least on LCD. I'm still gonna get 480hz OLED display because I'm curious.
I have 2070 Super. Latest Call of Duty runs on 4k with good quality using DLSS with 60 fps and I can't notice at all (unless I look very closely, even with my 6k ProDisplay XDR) so yeah I was thinking of building a 5090 based computer and it will probably last many more years than my 2070 super with latest AI developments.
>Do my games look good
i d like to point you to r/FuckTAA
>Do my games run well
if the internal logic is still in sub 120 hz and it is a twichy game, then no
Any frame gen gains don’t improve latency so the usefulness is reduced
Nvidia reflex 2 is supposed to fix that. It will recenter the frame based on mouse movements.
The 5090's core increase (30%) is actually underwhelming compared to the 3090->4090 increase (60% more), but the real game changer is the memory improvements, both in size and bandwidth.
They held back. Had they used 32Gbps GDDR7, they would have reached 2.0TB/sec memory bandwidth. 36Gbps GDDR7 would have let them reach 2.25TB/sec. The GB202 also reportedly has significantly more compute cores, TMUs, ROPs, tensor cores and RT cores than the 5090 uses:
https://www.techpowerup.com/gpu-specs/nvidia-gb202.g1072
Maybe there is a RTX 5090 Ti being held in reserve. They could potentially increase the compute on it by 13% and the memory bandwidth on it by 25% versus the 5090.
I wonder if anyone will try to solder 36Gbps GDDR7 chips onto a 5090 and then increase the memory clock manually.
Jensen did say that in the presentation that compute performance isn't increasing at large enough scales to make enough change. The shift is moving to reliance on using AI to improve performance and there are additions in hardware to accommodate that.
Isn't not being kept a secret, its being openly discussed that they need to leverage AI for better gaming performance.
If you can use AI to go from 40fps to 120fps with near identical quality, then that's still an improvement
DLSS and DLAA are terrible for any high-movement Games Like FPS, racing games, Action Games. I wouldn't exactly call it near identical quality. To shareholders this may ring true, but most gamers know that these GPS gains are not worth it and don't use it.. (They still buy it tho)
That's not true, DLSS isn't terrible for high movement games.
I've been using DLSS for FPS and racing games since I got my 3080 on launch and it works perfectly fine.
Frame gen might be a different story and Nvidia are releasing improvements, but DLSS isn't terrible at all.
Flops went up 26% and power draw 28%.
So the biggest benefit is PCIe 5 and the faster/more memory (credit going to Micron).
This is one of the worst generational upgrades. They’re doing it to keep profits in the data center business.
not true. They have redesigned AI cores with a dramatically better DLSS4 model that takes advantage of the new cores. Frames have more details and also a third frame can be generated creating a 300% FPS bump.
This is maybe a dumb question, but why is it so hard to buy Nvidia GPUs?
I can understand lack of supply, but why can't I go on nvidia.com and buy something the same way I go on apple.com and buy hardware?
I'm looking for GPUs and navigating all these different resellers with wildly different prices and confusing names (on top of the already confusing set of available cards).
OK so there are a handful of effects at work at the same time.
1. Many people knew the new series of nvidia cards was about to be announced, and nobody wanted to get stuck with a big stock of previous-generation cards. So most reputable retailers are just sold out.
2. With lots of places sold out, some scalpers have realised they can charge big markups. Places like Amazon and Ebay don't mind if marketplace sellers charge $3000 for a $1500-list-price GPU.
3. For various reasons, although nvidia makes and sells some "founder edition" the vast majority of cards are made by other companies. Sometimes they'll do 'added value' things like adding RGB LEDs and factory overclocking, leading to a 10% price spread for cards with the same chip.
4. nvidia's product lineup is just very confusing. Several product lines (consumer, workstation, data centre) times several product generations (Turing, Ampere, Ada Lovelace) times several vram/performance mixes (24GB, 16GB, 12GB, 8GB) plus variants (Super, Ti) times desktop and laptop versions. That's a lot of different models!
nvidia also don't particularly want it to be easy for you to compare performance across product classes or generations. Workstation and server cards don't even have a list price, you can only get them by buying a workstation or server from an approved vendor.
Also nvidia don't tend to update their marketing material when products are surpassed, so if you look up their flagship from three generations ago it'll still say it offers unsurpassed performance for the most demanding, cutting-edge applications.
The workstation cards have MSRPs. The RTX 6000 Ada’s MSRP is $6799:
https://www.techpowerup.com/gpu-specs/rtx-6000-ada-generatio...
Nvidia (and AMD) make the "core", but they don't make a "full" graphics card. Or at least they don't mass produce them, I think Nvidia tried it with their "founders edition".
It's just not their main business model, it's been that way for many many years at this point. I'm guessing business people have decided that it's not worth it.
Saying that they are "resellers" isn't technically accurate. The 5080 you buy from ASUS will be different than the one you buy from MSI.
Nvidia also doesn't make the "core" (i.e. the actual chip). TSMC and Samsung make those. Nvidia designs the chip and (usually) creates a reference PCB to show how to make an actual working GPU using that chip you got from e.g. TSMC. Sometimes (especially in more recent years) they also sell that design as "founders" edition. But they don't sell most of their hardware directly to average consumers. Of course they also provide drivers to interface with their chips and tons of libraries for parallel computing that makes the most of their design.
Most people don't realize that Nvidia is much more of a software company than a hardware company. CUDA in particular is like 90% of the reason why they are where they are while AMD and Intel struggle to keep up.
It seems that they have been tightening what they allow their partners to do, which caused EVGA to break away as they were not allowed to deviate too much from the reference design.
That was mostly about Nvidia's pricing. It's basically impossible to compete economically with the founders editions because Nvidia doesn't charge themselves a hefty markup on the chip. That's why their own cards always sell out instantly and then the aftermarket GPU builders can fight to pick up the scraps. The whole idea of the founders edition seems to be to make a quick buck immediately after release. Long term it's much more profitable to sell the chip itself at a price that they would usually sell their entire GPU for.
This years founders edition is what I really want from a GPU. Stop wasting my 2nd PCIe slot because you've made it 3.5/4 slots BIG! It is insane that they are now cooling 575W with two slots in height.
I would suggest getting a case that has a set of inbuilt (typically vertically-oriented) expansion card slots positioned a distance away from the regular expansion card slots, mount your graphics card there, and connect it to the motherboard with a PCI-E riser cable. It's what I did and I kicked myself for not doing it years prior.
I have no experience with PCI-E 5 cables, but I've a PCI-E 4 riser cable from Athena Power that works just fine (and that you can buy right now on Newegg). It doesn't have any special locking mechanism, so I was concerned that it would work its way off of the card or out of the mobo slot... but it has been in place for years now with no problem.
Can you link to an example case and riser cable?
I shouldn't have to link to the cable given that I said "Athena Power" and "Newegg", but sure, here you go. [0] Their Newegg store is here. [1] (They also sell that cable in different lengths.)
The "away from motherboard expansion card slots feature" isn't particularly uncommon on cases. One case that came up with a quick look around is the Phanteks Enthoo Pro 2. [2] I've seen other case manufacturers include this feature, but couldn't be arsed to spend more than a couple of minutes looking around to find more than one example to link to.
Also, there are a few smaller companies out there that make adapters [3] that will screw into a 140mm fan mounting hole and serve as an "away from motherboard" mounting bracket. You would need to remove any grilles from the mounting hole to make use of this for a graphics card.
[0] https://www.newegg.com/athena-power-8-extension-cable-black/...
[1] https://www.newegg.com/Athena-Power/BrandStore/ID-1849
[2] https://phanteks.com/product/enthoo-pro-2-tg
[3] Really, they're usually just machined metal rectangular donuts... calling them "adapters" makes them sound fancier than they are.
Man, things are getting really large and unwieldy with these giant GPUs we have nowadays.
My theory is this is one of the ways nvidia is trying to force ML users to buy the $$$$$ workstation cards.
Can't put four 4090s into your PC if every 4090 is 3.5 slots!
You can do single slot 4090 cards using water cooling, so having enormous coolers is not forcing anyone to buy workstation cards to fit things. Alternatively, there are always cases designed for riser cables.
It is an ever uphill battle to compete with Nvidia as a AIB partner.
Nvidia has internal access to the new card way ahead of time, has aerodynamic and thermodynamic simulators, custom engineered boards full of sensors, plus a team of very talented and well paid engineers for months in order to optimize cooler design.
Meanwhile AIB partners is pretty much kept in the blind until a few months in advance. It is basically impossible for a company like EVGA to exist as they pride themselves in their customer support - the finances just does not make sense.
Which is why EVGA stopped working with Nvidia a few years ago... (probably mentioned elsewhere too).
https://www.electronicdesign.com/technologies/embedded/artic...
Yeah I should have said design, embarrassingly I used to work in a (fabless) semiconductor company.
Totally agree with the software part. AMD usually designs something in the same ball park as Nvidia, and usually has a better price:performance ratio at many price points. But the software is just too far behind.
AMDs driver software is more featureful and better than NVidia's offerings. GeForce Experience + the settings app combo was awful, the Nvidia App is just copying some homework, and integrating MSI Afterburner's freeware.
But the business software stack was, yes, best in class. But it's not so for the consumer!
I think they mean CUDA
I've bought multiple founders editions cards from the nvidia store directly. Did they stop doing that recently?
They still make reference founders editions. They sell them at Best Buy though, not directly.
Reference cards make up the vast minority of cards for a specific generation though. I looked for numbers and could not find them but they tend to be the Goldilocks of cards if you can grab one because they sell at msrp IIRC.
Yep, I scored a 3070 Founder's at launch and was very lucky, watching other people pay up to the MSRP of the 3090 to get one from elsewhere.
Didn't Nvidia piss of some of their board partners at some point. I think EVGA stopped making Nvidia based graphics cards because of poor behavior on Nvidia part?
Also aren't most of the business cards made by Nvidia directly... or at least Nvidia branded?
I wonder how much "it's not worth it". Surely it should have been at all profitable? (a honest question)it's not worth it.The founders edition ones that I had were not great gpus. They were both under cooled and over cooled. They had one squirrel cage style blower that was quite loud and powerful and ran bascially at no speed or full blast. But being that it only had the one airpath and one fan it got overwhelmed by dust or if that blower fan had issues the gpu over heated. The consumer / 3rd party made ones usually have multiple fans at lower speeds larger diameter, multiple flow paths, and more control. TL;DR they were better designed, nvidia took the data center ram as much air as you can in there approach which isn't great for your home pc.
Founders cards being worse than board partner models hasn't been true in like 8 years. They switched to dual axial rather than a single blower fan with the 20 series, which made the value of board partner models hard to justify.
Since then, Nvidia is locked in a very strange card war with their board partners, because Nvidia has all the juicy inside details on their own chips which they can just not give the same treatment to their partners, stacking the deck for themselves.
Also, the reason why blowers are bad is because the design can't really take advantage of a whole lot of surface area offered by the fins. There's often zero heat pipes spreading the heat evenly in all directions, allowing a hot spot to form.
good to know, I have a 980gtx, I had to rma it after a summer of overheating. good to know they've gotten better on their own cards.
This is supply and demand at work. NVIDIA has to choose to either sell consumer or high end and they can reserve so much resources from TSMC. Also, Apple has outsold hardware before or it has high demand when it releases but for NVIDIA they have nearly constant purchases throughout the year from enterprise and also during consumer product launches.
It is frustrating speaking as someone who grew up poor and couldn't afford anything, and now I finally can and nothing is ever in stock. Such a funny twist of events, but also makes me sad.
Imagine how sad you'd be if you were still poor.
If you think it is bad for Nvidia, give AMD a try. Go ahead and try to guess which GPU is the most powerful by model number. They give so many old parts new model numbers, or have old flagship parts they don't upgrade in the next generation that are still more powerful.
GPUs are in demand.
So scalpers want to make a buck on that.
All there is to it. Whenever demand surpasses supply, someone will try to make money off that difference. Unfortunately for consumers, that means scalpers use bots to clean out retail stores, and then flip them to consumers.
Without thinking about it too deeply I'm wondering if GPU demand is that much higher than let's say iPhone demand. I don't think I've ever heard of iPhones being scarce and rare and out of stock.
Apple very tightly controls their whole value chain. It's their whole thing. Nvidia "dgaf" they are raking in more cash than ever and they are busy trying to figure out what's at the end of the semi-rainbow. (Apparently it's a B2C AI box gimmick.)
I read your question and thought to myself "why is it so hard to buy a Steamdeck"? Available only in like 10 countries. Seems like the opposite problem, Valve doesn't use resellers but they can't handle international manufacturing/shipping themselves? At least I can get a Nvidia GPU anytime I want from Amazon, BestBuy or whatever.
> At least I can get a Nvidia GPU anytime I want from Amazon, BestBuy or whatever.
You can? Thought this thread was about how they're sold out everywhere.
Maybe, it is simply a legacy business model. Nvidia wasn't always a behemoth. In olden days they must be happy for someone else to manage the global distribution, marketing, service etc. Also, this gives an illusion of choice. You get graphic cards in different color, shape, RGB, water cooling combinations.
One way to look at is that the third party GPU packagers have a different set of expertise. They generally build motherboards, GPU holder boards, RAM, and often monitors and mice as well. All of these product PCBs are cheaply made and don't depend on the performance of the latest TSMC node the way the GPU chips do, more about ticking feature boxes at the lowest cost.
So nvidia wouldn't have the connections or skillset to do budget manufacturing of low-cost holder boards the way ASUS or EVGA does. Plus with so many competitors angling to use the same nvidia GPU chips, nvidia collects all the margin regardless.
Yet the FE versions end up cheaper than third party cards (at least by MSRP), and with fewer issues caused by the third parties cheaping out on engineering…
I've always assumed their add-in board (AIB) partners (like MSI, ASUS, Gigabyte, etc) are able to produce PCBs and other components at higher volumes and lower costs than NVIDIA.
Not just the production of the finished boards, but also marketing, distribution to vendors and support/RMA for defective products.
There is profit in this, but it’s also a whole set of skills that doesn’t really make sense for Nvidia.
It depends on the timing. I lucked out about a year ago on the 4080; I happened to be shopping in what turned out to be the ~1 month long window where you could just go to the nvidia site, and order one.
- [deleted]
Nvidia uses resellers as distributors. Helps build out a locked in ecosystem.
How does that help "build out a locked in ecosystem"? Again, comparing to Apple: they have a very locked-in ecosystem.
I don't think lock-in is the reason. The reason is more that companies like Asus and MSI have a global presence and their products are available on store shelves everywhere. NVIDIA avoids having to deal with building up all the required relationships and distribution, they also save on things like technical support staff and dealing with warranty claims directly with customers across the globe. The handful of people who get an FE card aside.
Nvidia probably could sell cards directly now, given the strength of their reputation (and the reality backing it up) for graphics, crypto, and AI. However, they grew up as a company that sold through manufacturing and channel partners and that's pretty deeply engrained in their culture. Apple is unusually obsessed with integration, most companies are more like Nvidia.
Apple locks users in with software/services. nVidia locks in add-in board manufacturers with exclusive arrangements and partner programs that tie access to chips to contracts that prioritize nVidia. It happens upstream of the consumer. It's always a matter of degree with this stuff as to where it becomes anti-trust, but in this case it's overt enough for governments to take notice.
The increasing TDP trend is going crazy for the top-tier consumer cards:
3090 - 350W
3090 Ti - 450W
4090 - 450W
5090 - 575W
3x3090 (1050W) is less than 2x5090 (1150W), plus you get 72GB of VRAM instead of 64GB, if you can find a motherboard that supports 3 massive cards or good enough risers (apparently near impossible?).
I got into desktop gaming at the 970 and the common wisdom (to me at least, maybe I was silly) was I could get away with a lower wattage power supply and use it in future generations cause everything would keep getting more efficient. Hah...
For the curious what I actually did was stop gaming and haven't bought a GPU since 2000's! GPU stuff is still interesting to me, though.
I stopped playing a lot of games post-2010/2014 or so.
Lots of games that are fine on Intel Integrated graphics out there.
I went from 970 to 3070 and it now draws less power on average. I can even lower the max power to 50% and not notice a difference for most games that I play.
Yeah, do like me, I lower settings from "ultra hardcore" to "high" and keep living fine on a 3060 at 1440p for another few gens.
I'm not buying GPUs that expensive nor energy consuming, no chance.
In any case I think Maxwell/Pascal efficiency won't be seen anymore, with those RT cores you get more energy draw, can't get around that.
I've actually reversed my GPU buying logic from the old days. I used to buy the most powerful bleeding edge GPU I could afford. Now I buy the minimum viable one for the games I play, and only bother to upgrade if a new game requires a higher minimum viable GPU spec. Also I generally favor gameplay over graphics, which makes this strategy viable.
Yeah, that's another fact.
I upgrade GPUs then keep launching League of Legends and other games that really don't need much power :)
I'm generally a 1080p@60hz gamer and my 3060 Ti is overpowered for a lot of the games I play. However, there are an increasing number of titles being released over the past couple of years where even on medium settings the card struggles to keep a consistent 60 fps frame rate.
I've wanted to upgrade but overall I'm more concerned about power consumption than raw total performance and each successive generation of GPUs from nVidia seems to be going the wrong direction.
I think you can get a 5060 and simply down volt it some, you'll get more or less the same performance while reducing power draw sensibly.
That's probably not going to be an option for me as I wanted to upgrade to something with 16 GB of vram. I do toy with running LLM inference and squeezing models to fit in 8 GB vram is painful. Since the 5070 non-ti has 12 GB of vram there is no hope that a 5060 would have more vram than that. So, at a minimum I'm stuck with the prospect of upgrading to a 5070 ti.
That's not the end of the world for me if I move to a 5070 ti and you are quite correct that I can downclock/undervolt to keep a handle on power consumption. The price makes it a bit of a hard pill to swallow though.
I feel similarly; I just picked up a second hand 6600 XT (similar performance to 3060) and I feel like it would be a while before I'd be tempted to upgrade, and certainly not for $500+, much less thousands.
8Gb VRAM isn't enough for newer games though.
I thought opposite. My powersupply is just another component. I'll upgrade it as I need to. But keeping it all quiet and cool...
I built a gaming PC aiming to last 8-10 years. I spent $$$ on MO-RA3 radiator for water cooling loop.
My view:
1. a gaming PC is almost always plugged into a wall powerpoint
2. loudest voices in the market always want "MOAR POWA!!!"
1. + 2. = gaming PC will evolve until it takes up the max wattage a powerpoint can deliver.
For the future: "split system aircon" built into your gaming PC.
Nvidia wants you to buy their datacenter or professional cards for AI. Those often come with better perf/W targets, more VRAM, and better form factors allowing for a higher compute density.
For consumers, they do not care.
PCIe Gen 4 dictates a tighter tolerance on signalling to achieve a faster bus speed, and it took quite a good amount of time for good quality Gen 4 risers to come to market. I have zero doubt in my mind that Gen 5 steps that up even further making the product design just that much harder.
In the server space there is gen 5 cabling but not gen 5 risers.
Do you mean OCuLink? Honestly, I never thought about how 1U+ rackmount servers handle PCIe Gen5 wiring/timing issues between NVMe drives (front), GPUs/NICs (rear), and CPUs (middle).> gen 5 cablingOCuLink has been superseded by MCIO. I was speaking of the custom gen 5 cabled nvme backplane most servers have.
This is the #1 reason why I haven’t upgraded my 2080 Ti. Using my laser printer while my computer is on (even if it’s idle) already makes my UPS freak out.
But NVIDIA is claiming that the 5070 is equivalent to the 4090, so maybe they’re expecting you to wait a generation and get the lower card if you care about TDP? Although I suspect that equivalence only applies to gaming; probably for ML you’d still need the higher-tier card.
The big grain of salt with that "the 5070 performs like a 4090" is that it is talking about having the card fake in 3 extra frames for each one it properly generates. In terms of actual performance boost a 5070 is about 10% faster than a 4070.
According to Nvidia [0], DLSS4 with Multi Frame Generation means "15 out of 16 pixels are generated by AI". Even that "original" first out of four frames is rendered in 1080p and AI upscaled. So it's not just 3 extra frames, it's also 75% of the original one.
[0] https://www.nvidia.com/en-us/geforce/news/dlss4-multi-frame-...
- [deleted]
Source for your 10% number?
I think people are speculating based on graphs Nvidia has on their product page.
I heard them say that in the Hardware Unboxed youtube video yesterday.
I think it's this one https://youtu.be/olfgrLqtXEo
I don’t see any testing performed in that video. Did I miss it?
No testing, they estimated from the available information.
Why would you have your laser printer connected to your UPS?
Does a laser printer need to be connected to a UPS?
Faulty iron in another room fried my LaserJet. UPS isn't just for loss of power, it should also protect from power spikes. Btw. printer was connected to a (cheap) surge protector strip which didn't help. On positive side nothing else was fried and laser was fixed for 40 euros.
Is it ironic that the electrically expensive part of the LaserJet, the fused, is pretty much an iron in a different format?
It's not connected to the UPS directly, it's causing voltage dip on the circuit tripping the UPS.
I would be careful connecting laser printers to consumer UPS products. On paper all the numbers may line up, but I don't know why you'd want to if you could otherwise avoid it.
If the printer causes your UPS to trip when merely sharing the circuit, imagine the impact to the semiconductors and other active elements when connected as a protected load.
no
Your UPS is improperly sized. A 5kW Victron Multiplus II with one Pylontech US5000 would cost you around €1600 and should be able to carry all your house, not just your printer.
Thanks for those recommendations. From a few minutes of searching, looks like they would cost 1.5x to 2x that in USA.
We decided to start very small, because we couldn't figure out from the websites of various backup energy installers who was least likely to grossly inflate specs and prices. So, we recently bought a low-end expandable Anker Solix C1000 for around $500 USD as manual reserve power, mainly for the fridge. It seems to be intended more for "glamping", but Anker has good reputation for various unrelated products.
That’s because you have a Brother laser printer which charges its capacitors in the least graceful way possible.
- [deleted]
- [deleted]
If my Brother laser printer starts while I have the ceiling fan going on the same circuit, the breaker will trip. That's the only thing in my house that will do it. It must be a huge momentary current draw.
This happens with my Samsung laser printer too, is it not all laser printers?
It's mostly the fuser that is sucking down all the power. In some models, it will flip on and off very quickly to provide a fast warm up (low thermal mass). You can often observe the impact of this in the lights flickering.
Please expand, I am intrigued!
Sounds like you might be more the target for the $3k 128GB DIGITS machine.
Weirdly they're advertising "1 petaflop of AI performance at FP4 precision" [1] when they're advertising the 5090 [2] as having 3352 "AI TOPS" (presumably equivalent to "3 petaflops at FP4 precision"). The closest graphics card they're selling is the 5070 with a GPU performing at 988 "AI TOPS" [2]....
[1] https://nvidianews.nvidia.com/news/nvidia-puts-grace-blackwe...
[2] https://www.nvidia.com/en-us/geforce/graphics-cards/50-serie...
It seems like they're entirely different units?
TOPS means Tera Operations Per Second.
Petaflops means Peta Floating Point Operations Per Second.
... which, at least to my uneducated mind here, doesn't sound comparable.
I'm assuming that the operations being referred to in both cases are fp4 floating point operations. Mostly because
1. That's used for AI, so it's plausibly what they mean by "AI OPS"
2. It's generally a safe bet that the marketing numbers NVIDIA gives you is going to be for the fastest operations on the computers, and that those are the same for both computers when they're based on the same architecture.
Other than that, Terra is 10^12, Peta is 10^15, so 3352 Tera ops is 3.352 Peta ops and so on.
I’m really curious what training is going to be like on it, though. If it’s good, then absolutely! :)
But it seems more aimed at inference from what I’ve read?
I was wondering the same thing. Training is much more memory-intensive so the usual low memory of consumer GPUs is a big issue. But with 128GB of unified memory the Digits machine seems promising. I bet there are some other limitations that make training not viable on it.
Primarily concerned about the memory bandwidth for training.
Though I think I've been able to max out my M2 when using the MacBook's integrated memory with MLX, so maybe that won't be an issue.
Training is compute bound, not memory bandwidth bound. That is how Cerebras is able to do training with external DRAM that only has 150GB/sec memory bandwidth.
The architectures really aren't comparable. The Cerebras WSE has fairly low DRAM bandwidth, but it has a huge amount of on-die SRAM.
https://www.hc34.hotchips.org/assets/program/conference/day2...
They are training models that need terabytes of RAM with only 150GB/sec of memory bandwidth. That is compute bound. If you think it is memory bandwidth bound, please explain the algorithms and how they are memory bandwidth bound.
It will only have 1/40 performance of BH200, so really not enough for training.
Instead of risers just use pcie ender cords and you can get 4x 3090's working with a creator motherboard (google one that you know can handle 4). You could also use a mining case to do the same.
But, the advantage is that you can load a much more complex model easily (24GB vs 32GB is much easier since 24GB is just barely around 70B parameters).
You don't need to run them in x16 mode though. For inference even half that is good enough.
Performance per watt[1] makes more sense than raw power for most consumer computation tasks today. Would really like to see more focus on energy efficiency going forward.
That's s blind way to look at that imho. Doesn't work on me for sure.
More energy means more power consumption, more heat in my room, you can't escape thermodynamics. I have a small home office, it's 6 square meters, during summer energy draw in my room makes a gigantic difference in temperature.
I have no intention of drawing more than a total 400w top while gaming and I prefer compromising on lowering settings.
Energy consumption can't keep increasing over and over forever.
I can even understand it on flagships, they meant for enthusiasts, but all the tiers have been ballooning in energy consumption.
Increasing performance per watt means that you can get more performance using the same power. It also means you can budget more power for even better performance if you need it.
In the US the limiting factor is the 15A/20A circuits which will give you at most 2000W. So if the performance is double but it uses only 30% more power, that seems like a worthwhile tradeoff.
But at some point, that ends when you hit a max power that prevents people from running a 200W CPU and other appliances on the same circuit without tripping a breaker.
> Increasing performance per watt means that you can get more performance using the same power.
I'm currently running a 150 watt GPU, and the 5070 has a 250 TDP. You are correct. I could get a 5070 and down volt it to work in 150ish range e.g. and get almost the same performance (at least not significantly different to notice in game).
But I think you're missing the wider point of my complain: it's been from Maxwell that Nvidia hasn't produced major updates on the power consumption side of their architecture.
Simply making bigger and denser chips on better nodes while keeping to increase the power draw and slapping DLSS4 is not really an evolution, it's laziness and milking the users.
On top of that: the performance benefits we're talking about are really using DLSS4, which is artificially limited to the latest gen. I don't expect raw performance of this gen to exceed a 20% bump to the previous one when DLSS is off.
> But I think you're missing the wider point of my complain: it's been from Maxwell that Nvidia hasn't produced major updates on the power consumption side of their architecture.
Is this true or is it just that the default configuration draws a crazy amount of power? I wouldn't imagine running a 5090 downvolted to 75W is useful, but also I would like to see someone test it against an actual 75W card. I've definitely read that you can get 70% of the performance for 50% of the power if you downvolt cards, and it would be interesting to see an analysis of what the sweet spot is for different cards.
I remember various benchmarks in the years since Maxwell, when they took GPUs with comparable number of cuda cores and clocked them the same, the performance were in the delta of error suggesting that (raw) performance wise you're not getting much more since Maxwell (and that was what, 2013?).
I can confirm you that downvolting can get you the same tier of performance (-10%, which by the way is 3 fps when you're making 3 and 10 when you're making 100, negligible) by cutting power consumption by a lot, how much is that a lot depends on the specific gpu. On the 4090 you can get 90% of the performance at half the power draw, lower tier car have smaller gain/benefits ratios.
Today's hardware typically consumes as much power as it wants, unless we constrain it for heat or maybe battery.
If you're undervolting a GPU because it doesn't have a setting for "efficiency mode" in the driver, that's just kinda sad.
There may be times when you do want the performance over efficiency.
What I really don't like about it is low power GPUs appear to be a thing of the past essentially. An APU is the closest you'll come to that which is really somewhat unfortunate as the thermal budget for an APU is much tighter than it has to be for a GPU. There is no 75W modern GPU on the market.
the closest is the L4 https://www.nvidia.com/en-us/data-center/l4/ but its a bit weird.
RTX A4000 has an actual display output
Innodisk EGPV-1101
Sooo much heat .... I'm running a 3080 and playing anything demanding warms my room noticeably.
I wonder how many generations it will take until Nvidia launches a graphics card that needs 1kW.
I wish mining was still a thing, it was awesome to have free heating in the cold winter.
Is it not? (Serious question)
Probably not on GPUs - think it all moved to ASICs years ago.
Mining on GPUs was never very profitable unless you held the mined coins for years. I suspect it still is profitable if you are in a position to do that, but the entire endeavor seems extremely risky since the valuation increases are not guaranteed.
> Mining on GPUs was never very profitable unless you held the mined coins for years.
If mining is only profitable after holding, it wasn't profitable. Because then you could have spent less money to just buy the coins instead of mining them yourself, and held them afterwards.
Which didn't stop people gobbling up every available gpu in the late 2010's.
(Which, in my opinion, was a contributing factor why VR pc gaming didn't take of when better VR headsets arrived just around that point.)
you can still fold
In theory yes, but it also depends on the workload. RTX 4090 is ranking quite well on the power/performance scale. I'd rather have my card take 400W for 10 minutes to finish the job than take only 200W for 30 minutes.
I heavily power limited my 4090. Works great.
Yep. I use ~80% and barely see any perf degradation. I use 270W for my 3090 (out of 350W+).
It's good to know can all heat our bedrooms while mining shitcoins.
soon you'll need to plug your PC into the 240 V dryer outlet lmao
(with the suggested 1000 W PSU for the current gen, it's quite conceivable that at this rate of increase soon we'll run into the maximum of around 1600 W from a typical 110 V outlet on a 15 A circuit)
Can you actually use multiple videocards easily with existing AI model tools?
Yes, though how you do it depends on what you're doing.
I do a lot of training of encoders, multimodal, and vision models, which are typically small enough to fit on a single GPU; multiple GPUs enables data parallelism, where the data is spread to an independent copy of each model.
Occasionally fine-tuning large models and need to use model-parallelism, where the model is split across GPUs. This is also necessary for inference of the really big models, as well.
But most tooling for training/inference of all kinds of models supports using multiple cards pretty easily.
Yes, multi-GPU on the same machine is pretty straightforward. For example ollama uses all GPUs out of the box. If you are into training, the huggingface ecosystem supports it and you can always go the manual route to put tensors on their own GPUs with toolkits like pytorch.
I just made a video on this very thing: https://youtu.be/JtbyA94gffc
Yes. Depends what software you're using. Some will use more than one (e.g. llama.cpp), some commercial software won't bother.
most household circuits can only support 15-20 amps at the plug. there will be an upper limit to this and i suspect this is nvidia compromising on TDP in the short term to move faster on compute
So you are saying that Nvidia will finally force USA to the 220V standard? :)
Many American homes already have 240V sockets (eg: NEMA 14-30) for running clothes dryers, car chargers, etc. These can provide over 7200W continuous power!
I guess PC power supplies need to start adopting this standard.
I feel like every time I read about USA standards I inevitably discover that any and all SI standards are actually adopted somewhere in the USA - measures in the NASA, 24h clock in the army etc. Just not in the general populace. :)
The entire residential electrical grid in the USA uses 240v, split phase. One hot wire at 120v, one neutral at 0v, and one hot at -120v, out of phase with the other hot. Very rare to have anything else. It’s just that inside the building, the outlets/lights are connected to one side of the split phase connection or the other, giving you only 120v to work with. But then we have special outlets for electric clothes dryers, EV chargers, etc, which give you both hot connections in a single receptacle, for 240v.
You can't use a NEMA 14-30 to power a PC because 14-30 outlets are split-phase (that's why they have 4 prongs - 2 hot legs, shared neutral, shared ground). To my knowledge, the closest you'll get to split-phase in computing is connecting the redundant PSU in a server to a separate phase or a DC distribution system connected to a multi-phase rectifier, but those are both relegated to the datacenter.
You could get an electrician to install a different outlet like a NEMA 6-20 (I actually know someone who did this) or a European outlet, but it's not as simple as installing more appliance circuits, and you'll be paying extra for power cables either way.
If you have a spare 14-30 and don't want to pay an electrician, you could DIY a single-phase 240v circuit with another center tap transformer, though I wouldn't be brave enough to even attempt this, much less connect a $2k GPU to it.
As far as I’m aware (and as shown by a limited amount of testing that I’ve done myself), any modern PC PSU (with active PFC) is totally fine running on split-phase power: you just use both hots, giving you 240v across them, and the ground. The neutral line is unnecessary.
If you installed a European outlet in a US home then it would be using the same split phase configuration that a NEMA 14-30 does. But many appliances will work just fine, so long as they can handle 60 Hz and don't actually require a distinct neutral and ground for safety reasons. Likewise NEMA 10-30, the predecessor to NEMA 14-30 which is still found in older homes, does not have a ground pin.
I thought the main purpose of providing the neutral line was to be able to power mixed 240V and 120V loads.
PC power supplies already support 240V. Their connectors can take 120V or 240V.
Yes, but a standard household wall socket in the US supplies 120V @ 15A, for a max continuous power of 1.4 kW or so. So typical power supplies are only designed to draw up to that much power, or less.
If someone made a PC power supply designed to plug into a NEMA 14-50 you could run a lot of GPUs! And generate a lot of heat!
You just need the right adapters to connect the C14 connector on most PSUs to NEMA 14-50R. Use these two:
https://www.amazon.com/IronBox-Electric-Connector-Power-Cord...
https://www.amazon.com/14-50P-6-15R-Adapter-Adaptor-Charger/...
As long as the PSU has proper overcurrent protection, you could get away with saying it is designed for this. I suspect you meant designed for higher power draw rather than merely designed to be able to be plugged into the receptacle, but your remark was ambiguous.
Usually, the way people do things to get higher power draw is that they have a power distribution unit that provides C14 receptacles and plugs into a high power outlet like this:
https://www.apc.com/us/en/product/APDU9981EU3/apc-rack-pdu-9...
Then they plug multiple power supplies into it. They are actually able to use the full available AC power this way.
A (small) problem with scaling PSUs to the 50A (40A continuous) that NEMA 14-50 provides is that there is no standard IEC connector for it as far as I know. The common C13/C14 connectors are limited to 10A. The highest is C19/C20 for 16A, which is used by the following:
https://seasonic.com/atx3-prime-px-2200/
https://seasonic.com/prime-tx/
If I read the specification sheets correctly, the first one is exclusively for 200-240VAC while the second one will go to 1600W off 120V, which is permitted by NEMA 5-15 as long as it is not a continuous load.
There is not much demand for higher rated PSUs in the ATX form factor most here would want, but companies without brand names appear to make ones that go up to 3.6kW:
https://www.amazon.com/Supply-Bitcoin-Miners-Mining-180-240V...
As for even higher power ratings, there are companies that make them in non-standard form factors if you must have them. Here is one example:
https://www.infineon.com/cms/en/product/promopages/AI-PSU/#1...
The U.S. has been 240V for over a century. It uses split phase which has opposite phases on each hot line to let you take one and connect it to neutral to get 120V. If you connect both hot lines, you get 240V. For some reason, people in Europe and other places are unaware of this despite this having been the case since electrification happened in the early 20th century.
People are aware of this, but the regular sockets are connected to 120V only. You can (easily) hack an electrical circuit ("consumer unit" in UK) to deliver 240V on an existing plug, but that would be a very serious code violation. SO unless you hack your house circuits, you have 120V on regular sockets.
- [deleted]
You can replace the receptacles with ones meant for 240VAC at the same time you modify the wiring. Then it should be okay. Replacing the NEMA 5-15 receptacles with NEMA 6-15 receptacles would work.
Then you could also say that Europe uses 400 V. You get three-phase power with 230 V phases in your home, and high-powered appliances are often designed to use all three phases.
But when people speak of voltages, they usually mean what you get from a typical socket.
This explains why a number of people in Europe seem to love the idea of having triple phase to DC on board chargers on electric cars, even though it makes more sense to have those at the charging points.
That said, a typical socket likely varies more in the U.S. than in Europe since anything that is high draw in the U.S. gets 240VAC while Europe's 220VAC likely suffices for that. I actually have experimented with running some of my computers off 240VAC. It was actually better than 120VAC since the AC to DC conversion is more efficient when stepping down from 240VAC. Sadly, 240VAC UPS units are pricy, so I terminated that in favor of 120VAC until I find a deal on a 240VAC UPS unit.
I wonder if they will start putting lithium batteries in desktops so they can draw higher peak power.
There's a company doing that for stovetops, which I found really interesting (https://www.impulselabs.com)!
Unfortunately, when training on a desktop it's _relatively_ continuous power draw, and can go on for days. :/
Yeah that stove is what I was thinking of!
And good point on training. I don't know what use cases would be supported by a battery, but there's a marketable one I am sure we will hear about it.
They already use capacitors for that.
Batteries and capacitors would serve different functions. Capacitors primarily isolate each individual chip and subsystem on a PCB from high frequency power fluctuations when digital circuits switch or larger loads turn on or off. You would still need to use capacitors for that. The purpose of the batteries would be to support high loads on the order of minutes that exceed the actual wall plug capacity to deliver electricity. I am thinking specifically of the stove linked in your sibling comment, which uses lithium batteries to provide sustained bursts of power to boil a pot of water in tens of seconds without exceeding the power ratings of the wall plug.
It is the same function on different time scales. If you had a big enough capacitor, you could achieve the same thing. Not coincidentally, the capacitors in PSUs are huge, although not battery sized in terms of capacity. The purpose of the capacitors in the PSU is to keep things powered during a power outage to allow for a UPS to switch to battery. The technical term for this is PSU hold up time.
I consider smoothing out high frequency power fluctuations and providing power over a period of minutes that exceeds the capacity of the wall plug to be conceptually two different functions, even if they have similarities.
You’re right that a large enough capacitor could do that, and I’ve worked with high voltage supercapacitor systems which can provide tens of watts for minutes, but the cost is so high that lithium batteries typically make more sense.
Yes but the memory bandwidth of the 5090 is insanely high
Yeah, that's bullshit. I have a 3090 and I never want to use it at max power when gaming, because it becomes a loud space heater. I don't know what to do with 575W of heat.
Yeah. I've been looking at changing out my home lab GPU but I want low power and high ram. NVIDIA hasn't been catering to that at all. The new AMD APUs, if they can get their software stack to work right, would be perfect. 55w TDP and access to nearly 128GB, admittedly at 1/5 the mem bandwidth (which likely means 1/5 the real performance for tasks I am looking at but at 55w and being able to load 128g....)
Pretty interesting watching their tech explainers on YouTube about the changes in their AI solutions. Apparently they switched from CNNs to transformers for upscaling (with ray tracing support) if I understood correctly though for frame generation makes even more sense to me.
32 GB VRAM on the highest end GPU seems almost small after running LLMs with 128 GB RAM on the M3 Max, but the speed will most likely more than make up for it. I do wonder when we’ll see bigger jumps in VRAM though, now that the need for running multiple AI models at once seems like a realistic use case (their tech explainers also mentions they already do this for games).
If you have 128gb ram, try running MoE models, they're a far better fit for Apple's hardware because they trade memory for inference performance. using something like Wizard2 8x22b requires a huge amount of memory to host the 176b model, but only one 22b slice has to be active at a time so you get the token speed of a 22b model.
Project Digits... https://www.nvidia.com/en-us/project-digits/
I guess they're tired of people buying macs for AI.
I haven’t had great luck with the wizard as a counter point. The token generation is unbearably slow. I might have been using too large of a context window, though. It’s an interesting model for sure. I remember the output being decent. I think it’s already surpassed by other models like Qwen.
Long context windows are a problem. I gave Qwen 2.5 70b a ~115k context and it took ~20min for the answer to finish. The upside of MoE models vs 70b+ models is that they have much more world knowledge.
Do you have any recommendations on models to try?
Mixtral and Deepseek use MOE. Most others don't.
I planted garlic this year. Thanks for documenting! I can’t wait to see what I get harvest time.
I like the Llama models personally. Meta aside. Qwen is fairly popular too. There’s a number of flavors you can try out. Ollama is a good starting point to try things quickly. You’re def going to have to tolerate things crashing or not working imo before you understand what your hardware can handle.
Mixtral 8x22b https://mistral.ai/news/mixtral-8x22b/
In addition to the ones listed by others, WizardLM2 8x22b (was never officially released by Microsoft but is available).
You can also run the experts on separate machines with low bandwidth networking or even the internet (token rate limited by RTT)
They are intentionally keeping the VRAM small on these cards to force people to buy their larger, more expensive offerings.
Maybe, but if they strapped these with 64gb+ wouldn’t that be wasted on folks buying it for its intended purpose? Gaming. Though the “intended use” is changing and has been for a bit now.
XX90 is only half a gaming card it's also the one the entire creative professional 3D CGI, AI, game dev industry runs on.
The only reason gaming doesn't use all the VRAM is because typically GPUs don't have all the VRAM. If they did then games would somehow find a way to use it.
Game engines are optimized for lowest common denominator, being in this case consoles. PC games are rarely exclusivities, so same engine has to make it running with least ram available and differences between versions are normally small.
One normally uses some ultra texture pack to utilize current gen card's memory fully on many games.
Consoles would have more VRAM too if these cards had more VRAM. It's not like they're made separately in isolation.
Not really, the more textures you can put into memory the faster they can do their thing.
PC gamers would say that a modern mid-range card (1440p card) should really have 16GB of vram. So a 5060 or even a 5070 with less than that amount is kind of silly.
hmmm, maybe they can had different offerings like 16GB, 32GB, 64GB, etc. Maybe we can even have 4 wheels on a car.
If the VRAM wasn't small, the cards would all get routed to non gaming uses. Remember the state of the market when the 3000 series was new?
Then they should sell more of them.
They can only make so many, that's part of the problem
They should contact Intel.
Why sell more when you can sell less for more
Saw someone else point out that potentially the culprit here isn’t nvidia but memory makers. It’s still 2gb per chip and has been since forever
GDDR7 apparently has the capability of 3gb per chip. As it becomes more available their could be more VRAM configurations. Some speculate maybe an RTX 5080 Super 24gb release next year. Wishful thinking perhaps.
So you're saying more VRAM costs more money? What a novel idea!
Conversely, this means you can pay less if you need less.
Seems like a win all around.
No gamers need such high VRAM, if you're buying Gaming cards for ML work you're doing it wrong.
> Gaming cards for ML work you're doing it wrong
lol okay. "doing it wrong" for a tenth of the cost.
And screwing gamers over by raising the prices by 2x. Fuck that.
Believe it or not, it's possible to be interested in both machine learning and videogames. That's ignoring the notion that it's somehow how screwing over gamers. Buy a fucking AMD card. They're great at gaming and you don't need CUDA anyways. Enjoy the long-term acceleration of GPU performance increases you're getting by the way. All that stuff comes from innovations made for workstation/DL setups.
Get an AMD GPU? Said no one ever.
It seems like the 90-series cards are going to be targeting prosumers again. People who play games but may use their desktop for work as well. Some people are doing AI training on some multiple of 3090/4090 today but historically the Titan cards that preceded the 90s cards were used by game developers, video editors and other content developers. I think NVIDIA is going to try to move the AI folks onto Digits and return the 90-series back to its roots but also add in some GenAI workloads.
It's Nvidia that considers them, "gaming cards". The market decides their use in reality though.
Their strategy is to sell lower-VRAM cards to consumers with the understanding that they can make more money on their more expensive cards for professionals/business. By doing this, though they're creating a gap in the market that their competitors could fill (in theory).
Of course, this assumes their competitors have half a brain cell (I'm looking at YOU, Intel! For fuck's sake give us a 64GB ARC card already!).
And if you buy the cards that Nvidia says are for gaming and then complain that they don't have good specs for ML, who is the fool exactly?
Games already exceed 16 GBs at 4k from years.
I exceed 16GB in Chrome.
That says more about Chrome than anything else.
I use Firefox and have an 8Gb card and only encounter problems when I have more than about 125 windows with about 10-20 tabs each.
Yes, I am a tab hoarder.
And yes, I am going to buy a 16Gb card soon. :P
1200 tabs isn't that many
That's why I need to get a 16Gb card. :P
System Ram != GPU VRAM
MS Flight Simulator 2024 can consume...who knows how much.
I know my 10 GB 3080 ran out of VRAM playing it on Ultra, and i was getting as low as 2 fps because I'm bottlenecked by the PCI-Express bus as it has to constantly page the entire working set of textures and models in and out.
I'm getting a 5090 for that, plus I want to play around with 7B parameter LLMs and don't want to quantize below 8 bits if I can help it.
I've regularly exceeded 24 GiB of VRAM in Microsoft Flight Simulator 2024. Imagine a huge airport environment with high levels of detail, plus AI aircraft in the ground and sky. Then, on top of that, terrain and textures of the surrounding environment.
And that's at 1440p, not even 4K. The resulting stutters are... not pretty.
forget the post but some dude had a startup piping his 3090 to use via cloudflare tunnels for his ai saas making 5 figures a month off of his 1k gpu that handled the work load, I'd say he was doing it more then right.
And if his volume grows 100x should we expect him to run his company off gaming gpus? Just because you can do something doesn't mean you should or that it's ideal.
There's a reason large companies are buying H100s and not 4090s. Despite what you guys think, serious ML work isn't done on the consumer cards for many reasons: FP16/FP8 TFLOPS, NVLINK, power consumption, physical space, etc.
tell us how to do it right.
Get your daddy's credit card and buy H100s like a serious person.
Totally agree. I call this the "Apple Model". Just like the Apple Mac base configurations with skimpy RAM and Drive capacities to make the price look "reasonable". However, just like Apple, NVIDIA does make really good hardware.
Well, they are gaming cards. 32GB is plenty for that.
Makes sense. The games industry doesn't want another crypto mining-style GPU shortage.
Is there actually less VRAM on the cards or is it just disabled?
GPU manufacturers have no reason to include additional memory chips of no use on a card.
This isn't like a cutdown die, which is a single piece with disabled functionality...the memory chips are all independent (expensive) pieces soldered on board (the black squares surrounding the GPU core):
https://cdn.mos.cms.futurecdn.net/vLHed8sBw8dX2BKs5QsdJ5-120...
Check out their project digits announcement, 128GB unified memory with infiniband capabilities for $3k.
For more of the fast VRAM you would be in Quadro territory.
If you want to run LLMs buy their H100/GB100/etc grade cards. There should be no expectation that consumer grade gaming cards will be optimal for ML use.
Yes there should be. We don’t want to pay literal 10x markup because the card is suddenly “enterprise”.
Totally unreasonable expectation. Sry. The cards are literally built for gamers for gaming. That they work for ML is a happy coincidence.
You can’t possibly be naive enough to believe that Nvidia’s Titan class cards were designed exclusively for gamers.
> There should be no expectation that consumer grade gaming cards will be optimal for ML use.
And yet it just so happens they work effectively the same. I've done research on an RTX 2070 with just 8 GB VRAM. That card consistently met or got close to the performance of a V100 albeit with less vram.
Why indicate people shouldn't use consumer cards? It's dramatically (like 10x-50x) cheaper. Is machine learning only for those who can afford 10k-50k USD workstation GPU's? That's lame and frankly comes across as gate keeping.
Honestly I can't really imagine how a person could reasonably have this stance. Just let folks buy hardware and use it however they want. Sure if may be less than optimal but it's important to remember that not everyone in the world has the money to afford an H100.
Perhaps you can explain some other better reason for why people shouldn't use consumer cards for ML? It's frankly kind of a rude suggestion in the absence of a better explanation.
If you can do research on a mid tier consumer card then more power to you. I'm specifically referencing the people who are complaining that the specs on consumer video game GPUs are not good for ML work. Like theres just no reasonable expectation that they will be.
Ah, I see what you mean. Yeah I think it comes from a place of viewing increase in VRAM as relatively low cost and therefore an artificial limitation of sorts used to differentiate between consumer and workstation products (and the respective price disparities).
Which may be true although there are more differences than just VRAM and I assume those market segments have different perceptions of the real value Gamers want it cheaper/faster, institutions want it closer to state of the art, more robust to lengthy workloads (as in year long training sessions), and better support from nvidia. Among other things.
Why are transformers a better fit for frame generation. Is it because they can better utilize context from the previous history of frames ?
> after running LLMs with 128 GB RAM on the M3 Max,
These are monumentally different. You cannot use your computer as an LLM. Its more novelty.
I'm not even sure why people mention these things. Its possible, but no one actually does this out of testing purposes.
It falsely equates Nivida GPUs with Apple CPUs. The winner is Apple.
Even though they are all marketed as gaming cards, Nvidia is now very clearly differentiating between 5070/5070 Ti/5080 for mid-high end gaming and 5090 for consumer/entry-level AI. The gap between xx80 and xx90 is going to be too wide for regular gamers to cross this generation.
The 4090 already seemed positioned as a card for consumer AI enthusiast workloads. But this $1000 price gap between the 5080 and 5090 seems to finally cement that. Though we're probably still going to see tons of tech YouTubers making videos specifically about how the 5090 isn't a good value for gaming as if it even matters. The people who want to spend $2000 on a GPU for gaming don't care about the value and everyone else already could see it wasn't worth it.
From all the communication I’ve had with Nvidia, the prevailing sentiment was that the 4090 was an 8K card, that happened to be good for AI due to vram requirements from 8K gaming.
However, I’m a AAA gamedev CTO and they might have been telling me what the card means to me.
Well, modern games + modern cards can't even do 4k at high fps and no dlss. 8k story is totally fairy tale. Maybe "render at 540p, display at 8k"-kind of thing?
P.S. Also, VR. For VR you need 2x4k at 90+ stable fps. There's (almost) no vr games though
> modern games + modern cards can't even do 4k at high fps
What "modern games" and "modern cards" are you specifically talking about here? There are plenty of AAA games released last years that you can do 4K at 60fps with a RTX 3090 for example.
> There are plenty of AAA games released last years that you can do 4K at 60fps with a RTX 3090 for example.
Not when you turn on ray tracing.
Also 60fps is pretty low, certainly isn't "high fps" anyway
This.
You can't get high frame rates with path tracing and 4K. It just doesn't happen. You need to enable DLSS and frame gen to get 100fps with more complete ray and path tracing implementations.
People might be getting upset because the 4090 is WAY more power than games need, but there are games that try and make use of that power and are actually limited by the 4090.
Case in point Cyberpunk and Indiana Jones with path tracing don't get anywhere near 100FPS with native resolution.
Now many might say that's just a ridiculous ask, but that's what GP was talking about here. There's no way you'd get more than 10-15fps (if that) with path tracing at 8K.
> Case in point Cyberpunk and Indiana Jones with path tracing don't get anywhere near 100FPS with native resolution.
Cyberpunk native 4k + path tracing gets sub-20fps on a 4090 for anyone unfamiliar with how demanding this is. Nvidia's own 5090 announcement video showcased this as getting a whopping... 28 fps: https://www.reddit.com/media?url=https%3A%2F%2Fi.redd.it%2Ff...
> Also 60fps is pretty low, certainly isn't "high fps" anyway
I’m sure some will disagree with this but most PC gamers I talk to want to be at 90FPS minimum. I’d assume if you’re spending $1600+ on a GPU you’re pretty particular about your experience.
I’m so glad I grew up in the n64/xbox era. You save so much money if you are happy at 30fps. And the games look really nice.
You can also save tons of money by combining used GPUs from two generations ago with a patientgamer lifestyle without needing to resort to suffering 30fps
I wish more games had an option for N64/Xbox-level graphics to maximize frame rate. No eye candy tastes as good as 120Hz feels.
I’m sure you could do N64 style graphics at 120Hz on an iGPU with modern hardware, hahaha. I wonder if that would be a good option for competitive shooters.
I don’t really mind low frame rates, but latency is often noticeable and annoying. I often wonder if high frame rates are papering over some latency problems in modern engines. Buffering frames or something like that.
Doom 2016 at 1080p with a 50% resolution scale (so, really, 540p) can hit 120 FPS on an AMD 8840U. That's what I've been doing on my GPD Win Mini, except that I usually cut the TDP down to 11-13W, where it's hitting more like 90-100 FPS. It looks and feels great!
Personally I've yet to see a ray tracing implementation that I would sacrifice 10% of my framerate for, let alone 30%+. Most of the time, to my tastes, it doesn't even look better, it just looks different.
- [deleted]
> Also 60fps is pretty low, certainly isn't "high fps" anyway
Uhhhhhmmmmmm....what are you smoking?
Almost no one is playing competitive shooters and such at 4k. For those games you play at 1080p and turn off lots of eye candy so you can get super high frame rates because that does actually give you an edge.
People playing at 4k are doing immersive story driven games and consistent 60fps is perfectly fine for that, you don't really get a huge benefit going higher.
People that want to split the difference are going 1440p.
Anyone playing games would benefit from higher frame rate no matter their case. Of course it's most critical for competitive gamers, but someone playing a story driven FPS at 4k would still benefit a lot from framerates higher than 60.
For me, I'd rather play a story based shooter at 1440p @ 144Hz than 4k @ 60Hz.
You seem to be assuming that the only two buckets are "story-driven single player" and "PvP multiplayer", but online co-op is also pretty big these days. FWIW I play online co-op shooters at 4K 60fps myself, but I can see why people might prefer higher frame rates.
Games other than esports shooters and slow paced story games exist, you know. In fact, most games are in this category you completely ignored for some reason.
Also nobody is buying a 4090/5090 for a "fine" experience. Yes 60fps is fine. But better than that is expected/desired at this price point.
This - latest Call of Duty game on my (albeit water cooled) 3080TI founders edition saw frame rates in the 90-100fps running natively at 4k (no DLSS).
Can't CoD do 60+ fps @1080p on a potato nowadays?... not exactly a good reference point.
4k90 is about 6 times that, and he probably has the options turned up.
I’d say the comparison is what’s faulty, not the example.
new cod is really unoptimized. on a few years old 3080 still getting 100 fps on 4k that's pretty great. if he uses some frame gen such as lossless he can get 120-150. Say what you will about nvidia prices but you do get years of great gaming out of them.
Honestly my water cooled 3080TI FE has been great. Wish it had more VRAM for VR (DCS, MSFS) but otherwise it’s been great.
Which block did you go with? I went with the EK Vector special edition which has been great, but need to look for something else if I upgrade to 5080 with their recent woes.
I just have the Alphacool AIO with a second 360 radiator.
I’ve done tons of custom stuff but was at a point where I didn’t have the time for a custom loop. Just wanted plug and play.
Seen some people talking down the block, but honestly I run 50c under saturated load at 400 watts, +225 core, +600 memory with a hot spot of 60c and VRAM of 62c. Not amazing but it’s not holding the card back. That’s with the Phanteks T30’s at about 1200RPM.
Stock cooler I could never get the card stable despite new pads and paste. I was running 280 watts, barely able to run -50 on the core and no offset on memory. That would STILL hit 85c core, 95c hotspot and memory.
Yep. Few AAA games can run at 4K60 at max graphics without upscaling or frame gen on a 4090 without at least occasionally dipping below 60. Also, most monitors sold with VRR (which I would argue is table stakes now) are >60FPS.
The 4080 struggles to play high end games at 4k and there aren't that many 8k tvs/monitors in the market... Doesn't make much sense that anyone would think about the 4090 as an 8k GPU to be honest.
I recall them making the same claims about the 3090:
https://www.nvidia.com/en-us/geforce/news/geforce-rtx-3090-8...
Seems kinda silly to make an 8K video card when ... nobody on the planet has an 8K screen
Perhaps you don't, but several of us do. They've been around a while, available in your local bestbuy/costco if you're rocking a 4:4:4 TV they're not even particularly pricey and great for computing (depending on the subpixel layout).
On the planet? Many people. Maybe you're thinking 12K or 16K.
It's been a few years since I worked at [big tech retailer], but 8K TVs basically didn't sell at the time. There was basically no native content - even the demos were upscaled 4K - and it was very hard to tell the difference between the two unless you were so close to the screen that you couldn't see the whole thing. For the content that was available, either you were dealing with heavy compression or setting up a high-capacity server, since file sizes basically necessitated most of the space on what people would consider a normal-sized hard drive to store just a few movies.
The value just wasn't there and probably won't ever be for most use cases. XR equipment might be an exception, video editing another.
I got 4K TVs for both of my kids, they're dirt cheap-- sub $200. I'm surprised the Steam hardware survey doesn't show more. A lot of my friends also set their kids up on TVs, and you can't hardly buy a 1080P TV anymore.
Does Steam hardware survey show the resolution of your usual desktop, or your gaming resolution? eg I run at 4k in Windows normally, but quite often run games at 1080p.
I'd bet it's either the native display resolution or whatever you had for your desktop when submitted. They're able to gather all kinds of hardware specs so I'd lean to the native resolution as the most likely answer.
2018 (6 years ago): https://www.techradar.com/reviews/dell-ultrasharp-up3218k
It's uncommon, sure, but as mentioned it was sold to me as being a development board for future resolutions.
> Seems kinda silly to make a 4K video card when ... nobody on the planet has a 4K screen.
Someone else probably said that years ago when everyone was rocking 1080/1440p screens.
If you look at the Steam hardware survey you’ll find the majority of gamers are still rocking 1080p/1440p displays.
What gamers look for is more framerate not particularly resolution. Most new gaming monitors are focusing on high refresh rates.
8K feels like a waste of compute for a very diminished return compared to 4K. I think 8K only makes sense when dealing with huge displays, I’m talking beyond 83 inches, we are still far from that.
Gaming aside, 4K is desirable even on <30" displays, and honestly I wouldn't mind a little bit more pixel density there to get it to true "retina" resolution. 6K might be a sweet spot?
Which would then imply that you don't need a display as big as 83" to see the benefits from 8K. Still, we're talking about very large panels here, of the kind that wouldn't even fit many computer desks, so yeah...
First consumer 4K monitors came out more than a decade ago. I think the Asus PQ321 in 2013. That’s close to where we are now with 8K.
How many of the cards of that time would you call “4K cards”? Even the Titan X that came a couple of years later doesn’t really cut it.
There’s such a thing as being too early to the game.
Gaming isn't the only use-case, but Steam hardware survey says ~4% of users are using 4k screens. So the market is still small.
Why does 8K gaming require more VRAM?
I think the textures and geometry would have the same resolution (or is that not the case? but in 4K if you walk closer to the wall you'd want higher texture resolution as well anyway, if the graphics artists have made the assets at that resolution anyway)
8K screen resolution requires 132 megabytes of memory to store the pixels (for 32-bit color), that doesn't explain gigabytes of extra VRAM
I'd be curious to know what information I'm missing
My understand is between double buffering and multiple sets of intermediate info for shaders, you usually have a bunch of screen size buffers hanging around in VRAM, though you are probably right that these aren't the biggest contributor to VRAM usage in the end.
Shadow maps are a good example, if the final rendered image is 4k you don't want to be rendering shadow maps for each light source which are only 1080p else your shadows will be chunkier.
You’re only thinking of the final raster framebuffer, there are multiple raster and shader stages. Increasing the native output has an nearly exponential increase in memory requirements.
When you render a higher resolution natively, you typically also want higher resolution textures and more detailed model geometry.
I do recall an 8K push but I thought that was on the 3090 (and was conditional on DLSS doing the heavy lifting). I don't remember any general marketing about the 4090 being an 8K card but I could very well have missed it or be mixing things up! I mean it does make sense to market it for 8K since anyone who is trying to drive that many pixels when gaming probably has deep pockets.
I recall the 3090 8K marketing too. However, I also recall Nvidia talking about 8K in reference to the 4090:
https://www.nvidia.com/en-us/geforce/technologies/8k/
That said, I recall that the media was more enthusiastic about christening the 4090 as an 8K card than Nvidia was:
https://wccftech.com/rtx-4090-is-the-first-true-8k-gaming-gp...
If I recall correctly, the 3090, 3090 Ti and 4090 were supposed to replace the Titan cards that had been Nvidia's top gaming cards, but were never meant for gaming.
Someone very clever at Nvidia realized that if they rename their professional card (Titan) to be part of their "gaming" line, you can convince adults with too much disposable income that they need it to play Elden Ring.
I didn't know of anyone who used the Titan cards (which were actually priced cheaper than their respective xx90 cards at release) for gaming, but somehow people were happy spending >$2000 when the 3090 came out.
As an adult with too much disposable income and a 3090, it just becomes a local LLM server w/ agents when I'm not playing games on it. Didn't even see the potential for it back then, but now I'm convinced that the xx90 series offers me value outside of just gaming uses.
>but somehow people were happy spending >$2000 when the 3090 came out
Of course they did, the 3090 came out at the height of the pandemic and crypto boom in 2020, when people were locked indoors with plenty of free time and money to spare, what else where they gonna spend it on?
I wonder if these will be region-locked (eg, not for HK SAR).
The only difference is scalar. That isn't differentiating, that's segregation.
It won't stop crypto and LLM peeps from buying everything (one assumes TDP is proportional too). Gamers not being able to find an affordable option is still a problem.
>Gamers not being able to find an affordable option is still a problem.
Used to think about this often because I had a side hobby of building and selling computers for friends and coworkers that wanted to get into gaming, but otherwise had no use for a powerful computer.
For the longest time I could still put together $800-$1000 PC's that could blow consoles away and provide great value for the money.
Now days I almost want to recommend they go back to console gaming. Seeing older ps5's on store shelves hit $349.99 during the holidays really cemented that idea. Its so astronomically expensive for a PC build at the moment unless you can be convinced to buy a gaming laptop on a deep sale.
One edge that PCs have is massive catalog.
Consoles have historically not done so well with backwards compatibility (at most one generation). I don't do much console gaming but _I think_ that is changing.
There is also something to be said about catalog portability via something like a Steam Deck.
Cheaper options like the Steam Deck are definitely a boon to the industry. Especially the idea of "good enough" gaming at lower resolutions on smaller screens.
Personally, I just don't like that its attached to steam. Which is why I can be hesitant to suggest consoles as well now that they have soft killed their physical game options. Unless you go out of your way to get the add-on drive for PS5, etc
Its been nice to see backwards compatibility coming back in modern consoles to some extent with Xbox especially if you have a Series-X with the disc drive.
I killed my steam account with 300+ games just because I didn't see a future where steam would actually let me own the games. Repurchased everything I could on GoG and gave up on games locked to Windows/Mac AppStores, Epic, and Steam. So I'm not exactly fond of hardware attached to that platform, but that doesn't stop someone from just loading it up with games from a service like GoG and running them thru steam or Heroic Launcher.
2024 took some massive leaps forward with getting a proton-like experience without steam and that gives me a lot of hope for future progress on Linux gaming.
>Unless you go out of your way to get the add-on drive for PS5
Just out of interest, if I bought a PS5 with the drive, and a physical game, would that work forever (just for single-player games)?
Like you, I like to own the things I pay for, so it's a non-starter for me if it doesn't.
In my experience it varies on a game by game basis. Some games have limitations (ie. Gran Turismo 7 having only Arcade mode offline)
Are crypto use cases still there? I thought that went away after eth switched their proof model.
Bitcoin is still proof of work.
Yeah but BTC is not profitable on GPU I thought (needs ASIC farms)
Yup, the days of the value high end card are dead it seems like. I thought we would see a cut down 4090 at some point last generation but it never happened. Surely there's a market gap somewhere between 5090 and 5080.
The xx90 cards are really Titan cards. The 3090 was the successor to the Titan RTX, while the 3080 Ti was the successor to the 2080 Ti, which succeeded the 1080 Ti. This succession continued into the 40 series and now the 50 series. If you consider the 2080 Ti to be the "value high end card" of its day, then it would follow that the 5080 is the value high end card today, not the 5090.
In all those historical cases the second tier card was a cut down version of the top tier one. Now the 4080 and 5080 are a different chip and there's a gulf of a performance gap between them and the top tier. That's the issue I am highlighting, the 5080 is half a 5090, in the past a 3080 was only 10% off a 3090 performance wise.
It was not actually. The last time this was the case was Maxwell:
https://www.techpowerup.com/gpu-specs/nvidia-gm200.g772
Beginning with Pascal, Nvidia’s top GPU was not available in consumer graphics cards:
https://www.techpowerup.com/gpu-specs/nvidia-gp100.g792
Turing was a bit weird since instead of having a TU100, they instead had Volta’s GV100:
https://www.techpowerup.com/gpu-specs/nvidia-tu102.g813
https://www.techpowerup.com/gpu-specs/nvidia-gv100.g809
Then there is Ampere’s GA100 that never was used in a consumer graphics card:
https://www.techpowerup.com/gpu-specs/nvidia-ga100.g931
Ada was again weird as instead of a AD100, it had the GH100:
https://www.techpowerup.com/gpu-specs/nvidia-ad102.g1005
https://www.techpowerup.com/gpu-specs/nvidia-gh100.g1011
Now with Blackwell the GB100 is the high end one that is not going into consumer cards. The 5090 gets GB202 and the 5080 gets GB203.
Rather than the 40 series and 50 series putting the #2 GPU die into the #2 consumer card, they are putting the #3 GPU die into the #2 consumer card.
This is not relevant to what is being discussed. I clearly mean top tier consumer GPU.
3080/3090 - Same die
2080 ti/Titan RTX - Same die
1080 ti/Titan Xp - Same die
980 ti/Titan X - Same die
780/Titan - Same die
670/680 - Same die
570/580 - Same die
470/480 - Same die
Yes, but Nvidia thinks enough of them get pushed up to the 5090 to make the gap worthwhile.
Only way to fix this is for AMD to decide it likes money. I'm not holding my breath.
AMD announced they aren't making a top tier card for the next generation and is focusing on mid-tier.
Next generation, the are finally reversing course and unifying their AI and GPU architectures (just like nVidia).
2026 is the big year for AMD.
AMD's GPU marketing during CES has been such a shit show. No numbers, just adjectives and vibes. They're either hiding their hand, or they continue to have nothing to bring to the table.
Meanwhile their CPU marketing has numbers and graphs because their at the top of their game and have nothing to hide.
I'm glad they exist because we need the competition, but the GPU market continues to look dreary. At least we have a low/mid range battle going on between the three companies to look forward to for people with sensible gaming budgets.
Don't necessarily count Intel out.
Intel is halting its construction of new factories and mulling over whether to break up the company...
Intel's Board is going full Kodak.
I wouldn't count Intel out in the long term, but it'll take quite a few generations for them to catch up and who knows what the market will be like by then
Intel hate making money even more than AMD.
Intel's Arc B580 budget card is selling like hotcakes... https://www.pcworld.com/article/2553897/intel-arc-b580-revie...
They fired the CEO for daring to make a product such as this. The 25mil they paid to get rid of him might even wipe out their profits on this product.
Starting around 2000, Intel tried to make money via attempts at everything but making a better product (pushing RAMBUS RAM, itanium, cripling low-end chips more than they needed to be, focusing more on keeping chip manufacturing in-house thereby losing out on economy of scale). The result was engineers were (not always, but too often) nowhere near the forefront of technology. Now AMD, NVIDIA, ARM are all chipping away (pun intended).
It's not dissimilar to what happened to Boeing. I'm a capitalist, but the current accounting laws (in particular corporate taxation rules) mean that all companies are pushed to use money for stock buybacks than R&D (which Intel spent more on the former over the latter over the past decade and I'm watching Apple stagnate before my eyes).
- [deleted]
You underestimate how many gamers got a 4090.
Nvidia is also clearly differentiating the 5090 as the gaming card for people who want the best and an extra thousand dollars is a rounding error. They could have sold it for $1500 and still made big coin, but no doubt the extra $500 is pure wealth tax.
It probably serves to make the 4070 look reasonably priced, even though it isn't.
Gaming enthusiasts didn't beat an eye at 4090 price and won't beat one there either.
4090 was already priced for high income (in first world countries) people. Nvidia saw 4090s were being sold on second hand market way beyond 2k. They merely milking the cow.
Double the bandwidth, double the ram, double the pins, and double the power isn't cheap. I wouldn't be surprised if the profit on the 4090 was less than the 4080, especially since any R&D costs will be spread over significantly less units.
There have been numerous reports over the years that the 4090 actually outsold the 4080.
The 4080 was also quite the bad value compared to the much better 4090. That remains to be seen for the 5000 series.
The 4080 was designed as a strawman card expressly to drive sales towards the 4090. So this is by design.
Leaks indicate that the PCB has 14 layers with a 512-bit memory bus. It also has 32GB of GDDR7 memory and the die size is expected to be huge. This is all expensive. Would you prefer that they had not made the card and instead made a lesser card that was cheaper to make to avoid the higher price? That is the AMD strategy and they have lower prices.
That PCB is probably a few dollars per unit. The die is probably the same as the one in the 5070. I've no doubt it's an expensive product to build, but that doesn't mean the price is cost plus markup.
Currently, the 5070 is expected to use the GB205 die while the 5090 is expected to use the GB202 die:
https://www.techpowerup.com/gpu-specs/geforce-rtx-5070.c4218
https://www.techpowerup.com/gpu-specs/geforce-rtx-5090.c4216
It is unlikely that the 5070 and 5090 share the same die when the 4090 and 4080 did not share same die.
Also, could an electrical engineer estimate how much this costs to manufacture:
https://videocardz.com/newz/nvidia-geforce-rtx-5090-pcb-leak...
Is the last link wrong? It doesn't mention cost.
The PCB cost did not leak. We need an electrical engineer to estimate the cost based on what did leak.
>That PCB is probably a few dollars per unit.
It’s not. 14L PCB are expensive. When I looked at Apple cost for their PCB it was probably closer to $50, and they have smaller area
The price of a 4090 already was ~1800-2400€ where I live (not scalper prices, the normal online Shops)
We'll have to see how much they'll charge for these cards this time, but I feel like the price bump has been massively exaggerated by people on HN
MSRP went from 1959,- to 2369,-. That's quite the increase.
The 4090 MSRP was 1600
https://www.nvidia.com/en-us/geforce/graphics-cards/40-serie...
The cards were then sold around that ballpark you said, but that was because the shops could and they didn't say no to more profit.
We will have to wait to see what arbitrary prices the shops will set this time.
If they're not just randomly adding 400+ on top, then the card would cost roughly the same.
How will a 5090 compare against project digits? now that they're both in the front page :)
We will not really know until memory bandwidth and compute numbers are published. However, Project Digits seems like a successor to the NVIDIA Jetson AGX Orin 64GB Developer Kit, which was based on the Ampere architecture and has 204.8GB/sec memory bandwidth:
https://www.okdo.com/wp-content/uploads/2023/03/jetson-agx-o...
The 3090 Ti had about 5 times the memory bandwidth and 5 times the compute capability. If that ratio holds for blackwell, the 5090 will run circles around it when it has enough VRAM (or you have enough 5090 cards to fit everything into VRAM).
Very interesting, thanks!
32gb for the 5090 vs 128gb for digits might put a nasty cap on unleashing all that power for interesting models.
Several 5090s together would work but then we're talking about multiple times the cost (4x$2000+PC VS $3000)
Inference presumably will run faster on a 5090. If the 5x memory bandwidth figure holds, then token generation would run 5 times faster. That said, people in the digits discussion predict that the memory bandwidth will be closer to 546GB/sec, which is closer to 1/3 the memory bandwidth of the 5090, so a bunch of 5090 cards would only run 3 times faster at token generation.
Don't forget that you can link for example two 'Digits' together (~256 GB) if you want to run even larger models or have larger context size. That is 2x$3000 vs 8x$2000.
This will make it possible for you to run models up to 405B parameters, like Llama 3.1 405B at 4bit quant or the Grok-1 314B at 6bit quant.
Who knows, maybe some better models will be released in the future which are better optimized and won't need that much RAM, but it is easier to buy a second 'Digits' in comparison to building a rack with 8xGPUs. For example, if you look at the latest Llama models, Meta states: 'Llama 3.3 70B approaches the performance of Llama 3.1 405B'.
To interfere with Llama3.3-70B-Instruct with ~8k context length (without offloading), you'd need: - Q4 (~44GB): 2x5090; 1x 'Digits' - Q6 (~58GB): 2x5090; 1x 'Digits' - Q8 (~74GB): 3x5090; 1x 'Digits' - FP16 (~144GB): 5x5090; 2x 'Digits'
Let's wait and see which bandwidth it will have.
> bandwidth
Speculation has it at ~5XXgb/s.
agreed on the memory.
if I can I'll get a few but I fear they'll sell out immediately
Kind of wondering if nVidia will pull a Dell and copy Apple renaming
5070, 5070 Ti, 5080, 5090 to
5000, 5000 Plus, 5000 Pro, 5000 Pro Max.
:O
The 3090 and 3090 Ti both support software ECC. I assume that the 4090 has it too. That alone positions the xx90 as a pseudo-professional card.
The 4090 indeed does have ecc support
Yes, but ECC is inline, so it costs bandwidth and memory capacity.
Doesn't it always. (Except sometimes on some hw you can't turn it off)
I believe the cards that are intended for compute instead of GPU default to ECC being on and report memory performance with the overheads included.
Anything with DDR5 or above has built in limited ECC... it's required by the spec. https://www.corsair.com/us/en/explorer/diy-builder/memory/is...
Sure, but it's very limited. It doesn't detect or fix errors in the dimm (outside the chips), motherboard traces, CPU socket, or CPU.
It’s the same pricing from last year. This already happened.
32GB of GDDR7 at 1.8TB/sec for $2000, best of luck to the gamers trying to buy one of those while AI people are buying them by the truckload.
Presumably the pro hardware based on the same silicon will have 64GB, they usually double whatever the gaming cards have.
100% you will be able to buy them. And receive a rock in the package from Amazon.
At what point do we stop calling them graphics cards?
We've looped back to the "math coprocessor" days.
At what point did we stop calling them phones?
Compute cards, AI Cards, or Business Cards.
I like business cards, I'm going to stick with that one. Dibs.
Let's see Paul Allen's GPU.
Oh my god.
It even has a low mantissa FMA.
The tasteful thickness of it.
Nice.
Business Cards is an awesome naming :)
Nvidia literally markets H100 as a "GPU" (https://www.nvidia.com/en-us/data-center/h100/) even though it wasn't built for graphics and I doubt there's a single person or company using one to render any kind of graphics. GPU is just a recognizable term for the product category, and will keep being used.
Someone looked into running graphics on the A100, which is the H100's predecessor. He found that it supports OpenGL:
https://www.youtube.com/watch?v=zBAxiQi2nPc
I assume someone is doing rendering on them given the OpenGL support. In theory, you could do rendering in CUDA, although it would be missing access to some of the hardware that those who work with graphics APIs claim is needed for performance purposes.
The Amazon reviews for the H100 are amusing https://www.amazon.com/NVIDIA-Hopper-Graphics-5120-Bit-Learn...
General Purpose Unit.
General Processing Unit?
General Contact Unit (Very Little Gravitas Indeed).
It's a good question. I'll note that, even in the GPGPU days (eg BrookGPU), they were architecturally designed for graphics applications (eg shaders). The graphics hardware was being re-purposed to do something else. It was quite a stretch to do the other things compared to massively-parallel, general-purpose designs. They started adding more functionality to them, like physics. Now, tensors.
While they've come a long way, I'd imagine they're still highly specialized compared to general-purpose hardware and maybe still graphics-oriented in many ways. One could test this by comparing them to SGI-style NUMA machines, Tilera's tile-based systems, or Adapteva's 1024-core design. Maybe Ambric given it aimed for generality but Am2045's were DSP-style. They might still be GPU's if they still looked more like GPU's side by side with such architectures.
GPUs have been processing “tensors” for decades. What they added that is new is explicit “tensor” instructions.
A tensor operation is a generalization of a matrix operation to include higher order dimensions. Tensors as used in transformers do not use any of those higher order dimensions. They are just simple matrix operations (either GEMV or GEMM, although GEMV can be done by GEMM). Similarly, vectors are matrices, which are tensors. We can take this a step further by saying scalars are vectors, which are matrices, which are tensors. A scalar is just a length 1 vector, which is a 1x1 matrix, which is a tensor with all dimensions set to 1.
As for the “tensor” instructions, they compute tiles for GEMM if I recall my read of them correctly. They are just doing matrix multiplications, which GPUs have done for decades. The main differences are that you do not need need to write code to process the GEMM tile anymore as doing that is a higher level operation and this applies only to certain types introduced for AI while the hardware designers expect code using FP32 or FP64 to process the GEMM tile the old way.
Thanks for the correction and insights!
How long until a "PC" isn't CPU + GPU but just a GPU? I know CPUs are good for some things that GPUs aren't and vice versa but... it really kind of makes you wonder.
Press the power button, boot the GPU?
Surely a terrible idea, and I know system-on-a-chip makes this more confusing/complicated (like Apple Silicon, etc.)
Never. You can to a first approximation model a GPU as a whole bunch of slow CPUs harnessed together and ordered to run the same code at the same time, on different data. When you can feed all the slow CPUs different data and do real work, you get the big wins because the CPU count times the compute rate will thrash what CPUs can put up for that same number, due to sheer core count. However, if you are in an environment where you can only have one of those CPUs running at once, or even a small handful, you're transported back to the late 1990s in performance. And you can't speed them up without trashing their GPU performance because the optimizations you'd need are at direct odds with each other.
CPUs are not fast or slow. GPUs are not fast or slow. They are fast and slow for certain workloads. Contra popular belief, CPUs are actually really good at what they do, and the workloads they are fast at are more common than the workloads that GPUs are fast at. There's a lot to be said for being able to bring a lot of power to bear on a single point, and being able to switch that single point reasonably quickly (but not instantaneously). There's also a lot to be said for having a very broad capacity to run the same code on lots of things at once, but it definitely imposes a significant restriction on the shape of the problem that works for.
I'd say that broadly speaking, CPUs can make better GPUs than GPUs can make CPUs. But fortunately, we don't need to choose.
“Press the power button, boot the GPU” describes the Raspberry Pi.
Probably never if the GPU architecture resembles anything like they currently are.
I mean HPC people already call them accelerators
Do they double it via dual rank or clamshell mode? It is not clear which approach they use.
Why do you need one of those as a gamer? 1080ti was 120+ fps in heavy realistic looking games. 20xx RT slashed that back to 15 fps, but is RT really necessary to play games? Who cares about real-world reflections? And reviews showed that RT+DLSS introduced so many artefacts sometimes that the realism argument seemed absurd.
Any modern card under $1000 is more than enough for graphics in virtually all games. The gaming crisis is not in a graphics card market at all.
A bunch of new games are RT-only. Nvidia has aggressively marketed on the idea that RT, FG, and DLSS are "must haves" in game engines and that 'raster is the past'. Resolution is also a big jump. 4K 120Hz in HDR is rapidly becoming common and the displays are almost affordable (esp. so for TV-based gaming). In fact, as of today, Even the very fastest RTX 4090 cannot run CP2077 at max non-RT settings and 4K at 120fps.
Now, I do agree that $1000 is plenty for 95% of gamers, but for those who want the best, Nvidia is pretty clearly holding out intentionally. The gap between a 4080TI and a 4090 is GIANT. Check this great comparison from Tom's Hardware: https://cdn.mos.cms.futurecdn.net/BAGV2GBMHHE4gkb7ZzTxwK-120...
The biggest next-up offering leap on the chart is 4090.
I'm an ex-gamer, pretty recent ex-, and I own 4070Ti currently (just to show I'm not a grumpy GTX guy). Max settings are nonsensical. You never want to spend 50% of frame budget on ASDFAA x64. Lowering AA alone to barely noticeable levels makes a game run 30-50% faster*. Anyone who chooses a graphics card may watch benchmarks and basically multiply FPS by 1.5-2 because that's what playable settings will be. And 4K is a matter of taste really, especially in "TV" segment where it's a snakeoil resolution more than anything else.
* also you want to ensure your CPU doesn't C1E-power-cycle every frame and your frametimes don't look like EKG. There's much more to performance tuning than just buying a $$$$$ card. It's like installing a V12 engine into a rusted fiat. If you want performance, you want RTSS, AB, driver settings, bios settings, then 4090.
Many people are running 4k resolution now, and a 4080 struggles to to break 100 frames in many current games maxed (never-mind future titles) - therefore there's plenty of a market with gamers and the 5x series (myself included) who are looking for closer to 4090 performance at a non obscene price.
This is just absolutely false, Steam says that 4.21% of users play at 4K. The number of users that play at higher than 1440p is only 10.61%. So you are wrong, simply wrong.
This is a chicken and egg thing, though - people don't play at 4K because it requires spending a lot of $$$ on top-of-the-line GPU, not because they don't want to.
Did I say all the people, or did I say many people?..
Why are you so hostile? I'm not justifying the cost, I'm simply in the 4k market and replying to OP's statement "Any modern card under $1000 is more than enough for graphics in virtually all games" which is objectively false if you're a 4k user.
1080ti is most definitely not powerful enough to play modern games at 4k 120hz.
> is RT really necessary to play games? Who cares about real-world reflections?
I barely play video games but I definitely do
1. Because you shoot at puddles? 2. Because you play at night after a rainstorm?
Really, these are the only 2 situations where ray tracing makes much of a difference. We already have simulated shadowing in many games and it works pretty well, actually.
Yes, actually. A lot of games use water, a lot, in their scenes (70% of the planet is covered in it, after all), and that does improve immersion and feels nice to look at.
Silent Hill 2 Remake and Black Myth: Wukong both have a meaningful amount of water in them and are improved visually with raytracing for those exact reasons.
https://www.youtube.com/watch?v=cXpoJlB8Zfg
https://www.youtube.com/watch?v=iyn2NeA6hI0
Can you please point at the mentioned effects here? Immersion in what? Looks like PS4-gen Tomb Raider to me, honestly. All these water reflections existed long before RTX, it didn't introduce reflective surfaces. What it did introduce is dynamic reflections/ambience, which are a very specific thing to be found in the videos above.
does improve immersion and feels nice to look at
I bet that this is purely synthetic because RTX gets pushed down the players throat by not implementing any RTX-off graphics at all.
> by not implementing any RTX-off graphics at all.
Just taking this one, you actually make a point about having a raytracing-ready graphics card for me. If all the games are doing the hard and mathematically taxing reflection and light-bouncing work through raytracing now and without even an option for non-raytraced, then raytracing is where we're going and having a good RT card is, now or very soon, a requirement.
It’s not me making this point, but nvidia’s green paper agreements with particular studios to milk you for more money for basically same graphics we had at TR:ROTT. If you’re fine with that, godspeed. But “we” are not going anywhere RT “now”. Most of Steam plays on xx60 and equivalents, which cannot reasonably run RT-only, so there’s no natural incentive to go there.
I just find screen space effects a bit jarring
Indeed you're not a gamer, but you're the target audience for gaming advertisements and $2000 GPUs.
I still play traditional roguelikes from the 80s (and their modern counterparts) and I'm a passionate gamer. I don't need a fancy GPU to enjoy the masterpieces. Because at the end of the day nowhere in the definition of "game" is there a requirement for realistic graphics -- and what passes off as realistic changes from decade to decade anyway. A game is about gameplay, and you can have great gameplay with barely any graphics at all.
I'd leave raytracing to those who like messing with GLSL on shadertoy; now people like me have 0 options if they want a good budget card that just has good raster performance and no AI/RTX bullshit.
And ON TOP OF THAT, every game engine has turned to utter shit in the last 5-10 years. Awful performance, awful graphics, forced sub-100% resolution... And in order to get anything that doesn't look like shit and runs at a passable framerate, you need to enable DLSS. Great
I play roguelikes too
> Any modern card under $1000 is more than enough for graphics in virtually all games
I disagree. I run a 4070 Super, Ryzen 7700 with DDR5 and I still cant run Asseto Corsa Competizione in VR at 90fps. MSFS 2024 runs at 30 something fps at medium settings. VR gaming is a different beast
Spending $2 quadrillion on a GPU won't fix poor raster performance which is what you need when you're rendering two frames side by side. Transistors only get so small before AI slop is sold as an improvement.
> Who cares about real-world reflections?
Me. I do. I *love* raytracing; and, as has been said and seen for several of the newest AAA games, raytracing is no longer optional for the newest games. It's required, now. Those 1080s, wonderful as long as they have been (and they have been truly great cards) are definitely in need of an upgrade now.
You need as much FPS as possible for certain games for competitive play like Counter Strike.
I went from 80 FPS (highest settings) to 365 FPS (capped to my alienware 360hz monitor) when I upgraded from my old rig (i7-8700K and 1070GTX) to a new one ( 7800X3D and 3090 RTX)
You really want low latency in competitive shooters. From mouse, to game engine, to drivers, to display. There's a lot of nuance to this area, which hardware vendors happily suggest to just throw money at.
Btw, if you're using gsync or freesync, don't allow your display to cap it, keep it 2-3 frames under max refresh rate. Reddit to the rescue.
> Any modern card under $1000 is more than enough for graphics in virtually all games. The gaming crisis is not in a graphics card market at all.
You will love the RTX 5080 then. It is priced at $999.
It's a leisure activity, "necessary" isn't the metric to be used here, people clearly care about RT/PT while DLSS seems to be getting better and better.
These are perfect for games featuring path tracing. Not many games though but those really flex the 4090.
I get under 50fps in certain places in FF14. I run a 5900x with 32GB of ram and a 3090.
The 3090 + 5900x is a mistake. The 5900x is 2 x 5600x CPUs. So therefore, when the games asks for 8 cores, it will get 6 good cores and 2 very slow cores across the infinity switching fabric. What's more, NVidia GPUs take MUCH MORE CPU than AMD GPUs. You should either buy an AMD GPU or upgrade/downgrade to ANYTHING OTHER THAN 5900x with 8+ cores (5800x, 5800, 5700, 5700x3d, 5950x, 5900xt, anything really ...)
I've been looking hungrily at a 5700x3d, but just can't justify spending more money on AM4. I'm saving up for a 9800x3d.
I've considered just disabling a CCD to see how that works.
disabled once CCD. got 10fps in Limsa
bought a 5700x3d. got 30fps in Limsa
3D V-cache is magic.
The most interesting news is that the 5090 Founders' Edition is a 2-slot card according to Nvidia's website:
https://www.nvidia.com/en-us/geforce/graphics-cards/50-serie...
When was the last time Nvidia made a high end GeForce card use only 2 slots?
Fantastic news for the SFF community.
(Looks like Nvidia even advertises an "SFF-Ready" label for cards that are small enough: https://www.nvidia.com/en-us/geforce/news/small-form-factor-...)
It's a dual flow-through design, so some SFF cases will work OK but the typical sandwich style ones probably won't even though it'll physically fit
Not really, 575 watts for the GPU is going to make it tough to cool or provide power for.
There are 1000W SFX-L (and probably SFX) PSUs out there, and console-style cases provide basically perfect cooling through the sides. The limiting factor really is slot width.
(But I'm more eyeing the 5080, since 360W is pretty easy to power and cool for most SFF setups.)
Donno why I feel this, but probably going to end up being 2.5 slots
The integrator decides the form factor, not NVIDIA, and there were a few 2-slot 3080's with blower coolers. Technically water-cooled 40xx's can be 2-slot also but that's cheating.
40-series water blocks can even be single slot: https://shop.alphacool.com/en/shop/gpu-water-cooling/nvidia/...
> will be two times faster [...] thanks to DLSS 4
Translation: No significant actual upgrade.
Sounds like we're continuing the trend of newer generations being beaten on fps/$ by the previous generations while hardly pushing the envelope at the top end.
A 3090 is $1000 right now.
It looks like the new cards are NO FASTER than the old cards. So they are hyping the fake frames, fake pixels, fake AI rendering. Anything fake = good, anything real = bad.
Jensen thinks that "Moore's Law is Dead" and it's just time to rest and vest with regards to GPUs. This is the same attitude that Intel adopted 2013-2024.
Why are you upset how a frame is generated? We're not talking about free range versus factory farming. Here, a frame is a frame and if your eye can't tell the difference then it's as good as any other.
"a frame is a frame" - of course it isn't that makes no sense. The point of high frame rate is to have more frames that render the game state accurately for more subdivisions
Otherwise you could just duplicate every frame 100 times and run at 10k fps
Or hell just generate a million black frames every second, a frames a frame right
Latency and visual artifacts.
let me just apply my super proprietary machine learning architecture... ah yes it's done, behold, I can generate 3.69 trillion frames per second, because I compressed each frame to a single bit and that's how fast the CPU's memory bus is
He said "if your eyes can't tell the difference", which is obviously false in your case.
And obviously false with DLSS.
the main point of more fps is lower latency. if you're getting 1000 fps but they are all ai generated from a single real frame per second, your latency will be 500ms and the experience will suck
- [deleted]
Why is that a problem though? Newer and more GPU intensive games get to benefit from DLSS 4 and older games already run fine. What games without DLSS support could have done with a boost?
I've heard this twice today so curious why it's being mentioned so often.
I also like DLSS, but the OP is correct that it is a problem. Specifically it's a problem with understanding what are these cards capable of. Theoretically we would like to see separately performance with no upscaling at all, then separately with different levels of upscaling. Then we would be able to see easier what is the real performance boost of the hardware, and of the upscaler separately.
It's like BMW comparing new M5 model to the previous gen M5 model, while previous gen is on the regular 95 octane, and new gen is on some nitromethane boosted custom fuel. With no information how fast the new car is on a regular fuel.
How situation actually looks like will be revealed soon via independent tests. I'm betting its bit of both, no way they can't progress in 2 years raw performance at all, other segments still manage to achieve this. Even 10%, combined with say 25% boost with DLSS, nets nice FPS increase. I wish it could be more but we don't have a choice right now.
Does normal gamers actually notice any difference on some normal 4k low latency monitors/tvs? I mean any form of extra lag, screen tearing etc.
>no way they can't progress in 2 years raw performance at all
Seems like we're now in the Intel CPU stage where they just keep increasing the TDP to squeeze out a few more percentage points, and soon we'll see the same degradation from overheating that they did.
I for one don't like the DLSS/TAA look at all. Between the lack of sharpness, motion blur and ghosting, I don't understand how people can look at that and consider it an upgrade. Let's not even get into the horror that is frame generation. They're a graphics downgrade that gives me a headache and I turn the likes of TAA and DLSS off in every game I can. I'm far from alone in this.
So why should we consider to buy a GPU at twice the price when it has barely improved rasterization performance? An artificially generation-locked feature anyone with good vision/perception despises isn't going to win us over.
Do you find DLSS unacceptable even on "quality" mode without frame generation?
I've found it an amazing balance between quality and performance (ultra everything with quality DLSS looks and run way better than, say, medium without DLSS). But I also don't have great vision, lol.
We all know DLSS4 could be compatible with previous gens.
Nvidia has done that in the past already (see PhysX).
> What games without DLSS support could have done with a boost?
DCS World?
Has DLSS now
5090 has 2x the core, higher frequencies, 3x flops. You got to do some dd before talking
Which flops? For AI flops it’s only 25% faster than 4090 (3352 tflops vs 2642 tflops)
>A 3090 is $1000 right now.
Not really worth it if you can get a 5090 for $1,999
If you can get a 5090 for that price, I'll eat my hat. scalpers with their armies of bots will buy them all before you get a chance.
it is absurdly easy to get a 5090 on launch. ive gotten their flagship from their website FE every single launch without fail. from 2080 to 3090 to 4090
i absolutely do not believe you
Do you have a recipe in mind for preparing your hat for human consumption or is your plan to eat it raw?
Saving $1000 for only a ~25-30% hit in rasterization perf is going to be worth it for a lot of people.
That would be true for the 4090, but the 3090 is even more cut down so the 5090 is about 100% faster in rasterization (based on the 4090 being nearly 70% faster than the 3090 and the 5090 being approx 25% faster than the 4090)
The increase from a 3090 to a 5090 would be way more than that.
Certainly worth paying +$1k if you are doing anything that requires GPU power (hash cracking with hashcat for example)
> GeForce RTX 5070 Ti: 2X Faster Than The GeForce RTX 4070 Ti
2x faster in DLSS. If we look at the 1:1 resolution performance, the increase is likely 1.2x.
That's what I'm wondering. What's the actual raw render/compute difference in performance, if we take a game that predates DLSS?
We shall wait for real world benchmarks to address the raster performance increase.
The bold claim "5070 is like a 4090 at 549$" is quite different if we factor in that it's basically in DLSS only.
it's actually a lot worse than it sounds even. The 5070 is like a 4090 is when the 5070 has multi frame generation on and the 4090 doesn't. So it's not even comparable levels of DLSS, the 5070 is hallucinating 2x+ more frames than the 4090 is in that claim
Based on non-DLSS tests, it seems like a respectable ~25%.
Respectable outright, but 450W -> 575W TDP takes the edge off a bit. We'll have to see how that translates to at the wall. My room already gets far too hot with a 320W 3080.
Let's see the new version of frame generation. I enabled DLSS frame generation on Diablo 4 using my 4060 and I was very disappointed with the results. Graphical glitches and partial flickering made the game a lot less enjoyable than good old 60fps with vsync.
The new DLSS 4 framegen really needs to be much better than what's there in DLSS 3. Otherwise the 5070 = 4090 comparison won't just be very misleading but flatly a lie.
Seems like pretty heavily stretched truth. Looks like the actual performance uplift is more like 30%. The 5070=4090 comes from generating multiple fake frames per actual frame and using different versions of DLSS on the cards. Multiple frame generation (required for 5070=4090) increases latency between user input and updated pixels and can also cause artifacts when predictions don't match what the game engine would display.
As always wait for fairer 3rd party reviews that will compare new gen cards to old gen with the same settings.
> Multiple frame generation (required for 5070=4090) increases latency between user input and updated pixels
Not necessarily. Look at the reprojection trick that lots of VR uses to double framerates with the express purpose of decreasing latency between user movements and updated perspective. Caveat: this only works for movements and wouldn't work for actions.
There's some very early coverage on Digital Foundry where they got to look at the 5080 and Cyberpunk.
The main edge Nvidia has in gaming is ray tracing performance. I'm not playing any RT heavy titles and frame gen being a mixed bag is why I saved my coin and got a 7900 XTX.
I have a serious question about the term "AI TOPS". I find many conflicting definitions while others say nothing. A meaningful metric should at least be well defined on its own term, like in "TOPS" or expanded "Tera Operations Per Second", what operation it will measure?
Seemingly NVIDIA is just playing number games, like wow 3352 is a huge leap compared to 1321 right? But how does it really help us in LLMs, diffusion models and so on?
It would be cool if something like vast.ai's "DLPerf" would become popular enough for the hardware producers to start using it too.
> DLPerf (Deep Learning Performance) - is our own scoring function. It is an approximate estimate of performance for typical deep learning tasks. Currently, DLPerf predicts performance well in terms of iters/second for a few common tasks such as training ResNet50 CNNs. For example, on these tasks, a V100 instance with a DLPerf score of 21 is roughly ~2x faster than a 1080Ti with a DLPerf of 10. [...] Although far from perfect, DLPerf is more useful for predicting performance than TFLops for most tasks.
We don’t need this. We can easily unpack Nvidia’s marketing bullshit.
5090 is 26% higher flops than 4090, at 28% higher power draw, and 25% higher price.
The 5090 TOPS number is with sparsity at 4bits, so it doubles the value compared to the 8bit sparse number for 4090.
The real jump is 26%, at 28% higher power draw and 25% higher price.
A dud indeed.
It really sucks. BTW, how did you find the statement? I cannot find it in any place.
I didn’t find it. I dug up the real/raw numbers and did the math.
I will be astonished if I'll be able to get a 5090 due to availability. The 5080's comparative lack of memory is a buzzkill -- 16 GB seems like it's going to be a limiting factor for 4k gaming.
Does anyone know what these might cost in the US after the rumored tariffs?
Honestly, with how fast memory is being consumed nowadays and the increased focus on frame generation/interpolation vs “full frames”, I’ll keep my 3090 a little longer instead of upgrading to a 5080 or 5090. It’s not the fastest, but it’s a solid card even in 2025 for 1440p RT gaming on a VRR display, and the memory lets me tinker with LLMs without breaking a sweat.
If DLSS4 and “MOAR POWAH” are the only things on offer versus my 3090, it’s a hard pass. I need efficiency, not a bigger TDP.
Pricing for the next generation might be somewhat better if Nvidia switches to Samsung for 2nm like the rumors suggest:
https://wccftech.com/nvidia-is-rumored-to-switch-towards-sam...
Coincidentally, the 3090 was made using Samsung's 8nm process. You would be going from one Samsung fabricated GPU to another.
NVidia's pricing isn't based on how much it takes to produce their cards, but since they have no competition, it's purely based on how much consumers are grudgingly willing to pay up. If AMD continues to sleep, they'll sale these cards for the same price, even if they could produce them for free.
AMD is not sleeping. They publicly admitted that they threw in the towel- they have exited the high end market.
And if these 50-series specs are anything to go by, they made a good call in doing so. All the big improvements are coming in mid-range cards, where AMD, nVidia, and Intel(!) are trading blows.
If the only way to get better raw frames in modern GPUs is to basically keep shoveling power into them like an old Pentium 4, then that’s not exactly an enticing or profitable space to be in. Best leave that to nVidia and focus your efforts on a competitive segment where cost and efficiency are more important.
Nvidia’s Titan series cards always were outrageously priced for the consumer market. The 5090 is a Titan series card in all but name.
I suspect there is a correlation to the price that it costs Nvidia to produce these. In particular, the price is likely 3 times higher than the production and distribution costs. The computer industry has always had significant margins on processors.
Efficiency is why I switched from a 3090 to a 4080. The amount of heat generated by my PC was massively reduced with that change. Even if the xx90 weren't jumping up in price each generation, I wouldn't be tempted to buy one again (I didn't even really want the 3090, but that was during the supply shortages and it was all I could get my hands on).
DLSS4 is coming to other RTX cards, eventually. https://www.nvidia.com/en-us/geforce/news/dlss4-multi-frame-...
Note, the portions of DLSS4 that improve 2x frame generation performance/stability and the improved models for upscaling are coming to other rtx cards. DlSS4 multi-frame generation will not.
I use my 3090 on a 4K TV and still don't see a need, although a lot of that is being bored with most big budget games so I don't have many carrots to push me to upgrade.
Turn down a few showcase features and games still look great and run well with none or light DLSS. UE5 Lumen/ray tracing are the only things I feel limited on and until consoles can run them they'll be optional.
It seems all the gains are brute forcing these features with upscaling & frame generation which I'm not a fan of anyway.
Maybe a 7090 at this rate for me.
4k gaming is dumb. I watched a LTT video that came out today where Linus said he primarily uses gaming monitors and doesn't mess with 4k.
No it's not. 2560x1440 has terrible PPI on larger screens. Either way with a 4k monitor you don't technically need to game at 4k as most intensive games offer DLSS anyway.
What matters is the PPD, not the PPI, otherwise it's an unsound comparison.
Too much personal preference with PPD. When I upgraded to a 32" monitor from a 27" one i didn't push my display through my wall, it sat in the same position.
Not entirely clear on what you mean, but if you refuse to reposition your display or yourself after hopping between diagonal sizes and resolutions, I'd say it's a bit disingenuous to blame or praise either afterwards. Considering you seem to know what PPD is, I think you should be able to appreciate the how and why.
And FSR, which is cross gpu vendor.
Not anymore. FSR4 is AMD only, and only the new RDNA4 GPUs.
I have seen AMD's PR materials for RDNA4, and as far as I can tell, they do not say anywhere anything like that.
People read too much into "designed for RDNA4".
https://cdn.videocardz.com/1/2025/01/AMD-FSR4-9070.jpg
Why would they write that on their marketing slides?
Because it only works on these cards right now.
Further elaborated by their GPU marketing people on interviews. To summarize "RDNA4 for now" and "we're looking into supporting older...".
Yep. I have both 4k and 1440p monitors and I can’t tell the difference in quality so I always use the latter for better frames. I use the 4k for reading text though, it’s noticeably better.
That's why I also finally went from 1920x1200 to 4k about half a year ago. It was mostly for reading text and programming, not gaming.
I can tell the difference in games if I go looking for it, but in the middle of a tense shootout I honestly don't notice that I have double the DPI.
- [deleted]
There are good 4K gaming monitors, but they start at over $1200 and if you don't also have a 4090 tier rig, you won’t be able to get full FPS out of AAA games at 4k.
I still have a 3080 and game at 4K/120Hz. Most AAA games that I try can pull 60-90Hz at ~4K if DLSS is available.
Most numbers people are touting are from "Ultra everything benchmarks", lowering the settings + DLLS makes 4k perfectly playable.
I've seen analysis showing that DLSS might actually yield a higher quality image than barebones for the same graphics settings owing to the additional data provided by motion vectors. This plus the 2x speedup makes it a no brainer in my book.
Also, ultrawide monitors. They exist, provide more immersion. And typical resolution is 3440x1440 which is high and and the same time have low ppi (basically regular 27" 1440p monitor with extra width). Doubling that is way outside modern GPU capabilities
A coworker who is really into flight sims runs 6 ultrawide curved monitors to get over 180 degrees around his head.
I have to admit with the display wrapping around into peripheral vision, it is very immersive.
Almost no one plays on native 4k anyway. DLSS Quality (no framegen etc) renders at 1440p internally and by all accounts there is no drawback at all, especially above 60fps. Looks great, no noticeable (excluding super sweaty esports titles) lag and 30% more performance. Combined with VRR displays, I would say 4k is perfectly ok for gaming.
Taking anything Linus or LTT says seriously is even dumber....
I watched the same video you talking about [1], where he's trying the PG27UCDM (new 27" 4K 240Hz OLED "gaming monitor" [2]) and his first impressions are "it's so clean and sharp", then he starts Doom Eternal and after a few seconds he says "It's insane [...] It looks perfect".
[1] https://www.youtube.com/watch?v=iQ404RCyqhk
[2] https://rog.asus.com/monitors/27-to-31-5-inches/rog-swift-ol...
Nonsense 4k gaming was inevitable as soon as 4k TVs got mainstream.
Looks like a bit dud, though given their competition and where their focus is right now maybe expected.
Going from 60 to 120fps is cool. Going from 120fps to 240fps is in the realm of diminishing returns, especially because the added latency makes it a non starter for fast paced multiplayer games.
12GB VRAM for over $500 is an absolute travesty. Even today cards with 12GB struggle in some games. 16GB is fine right now, but I'm pretty certain it's going to be an issue in a few years and is kind of insane at $1000. The amount of VRAM should really be double of what it is across the board.
Looks like most of the improvement is only going to come when DLSS4 is in use and its generating most of the frame for Ray Tracing and then also generating 3 predicted frames. When you use all that AI hardware then its maybe 2x, but I do wonder how much fundamental rasterisation + shaders performance gain there is in this generation in practice on the majority of actual games.
There was some solid commentary on the Ps5Pro tech talk stating core rendering is so well optimized much of the gains in the future will come from hardware process technology improvements not from radical architecture changes. It seems clear the future of rendering is likely to be a world where the gains come from things like dlss and less and free lunch savings due to easy optimizations.
Nanite style rendering still seems fairly green. That could take off and they decide to re-implement the software rasterization in hardware.
Raster is believe it or not, not quite the bottleneck. Raster speed definitely _matters_, but it's pretty fast even in software, and the bigger bottleneck is just overall complexity. Nanite is a big pipeline with a lot of different passes, which means lots of dispatches and memory accesses. Same with material shading/resolve after the visbuffer is rendered.
EDIT: The _other_ huge issue with Nanite is overdraw with thin/aggregate geo that 2pass occlusion culling fails to handle well. That's why trees and such perform poorly in Nanite (compared to how good Nanite is for solid opaque geo). There's exciting recent research in this area though! https://mangosister.github.io/scene_agn_site.
> but I do wonder how much fundamental rasterisation + shaders performance gain there is in this generation in practice on the majority of actual games.
likely 10-30% going off of both the cuda core specs (nearly unchanged gen/gen for everything but the 5090) as well as the 2 benchmarks Nvidia published that didn't use dlss4 multi frame gen - Far Cry 6 & A Plague Tale
https://www.nvidia.com/en-us/geforce/graphics-cards/50-serie...
Given that Jensen completely omitted ANY MENTION of rasterization performance, I think we can safely assume it's probably WORSE in the 5000 series than the 4000 series, given the large price cuts applied to every card below then 5090 (NVidia was never happy charging $1000 for the 4080 super - AMD forced them to do it with the 7900xtx).
3 Generated frames sounds like a lot of lag, probably a sickening amount for many games. The magic of "blackwell flip metering" isn't quite described yet.
It’s 3 extrapolated frames not interpolated. So would be reduced lag at the expense of greater pop-in.
There’s also the new reflex 2 which uses reprojection based on mouse motion to generate frames that should also help, but likely has the same drawback.
Digital Foundry just covered this. 3x and 4x both add additional latency on top of 2x.
"Frame generation (FG)" was not a feature in DLSS 2 - the subthread starter was speculating about MFG (of DLSS 4) having worse latency than FG (of DLSS 3), on the basis of more interpolated frames meaning being more frames behind.
To me this sounds not quite right, because while yes, you'll technically be more frames behind, those frames are also presented for a that much shorter period. There's no further detail available on this it seems however, so people have pivoted to the human equivalent of LLM hallucinations (non-sequiturs and making shit up then not being able to support it, but also being 100% convinced they are able to and are doing so).
Nobody is talking about DLSS 2 here so I don't know where that came from. The 2x, 3x, and 4x in my post are the number of generated frames. So 2x == DLSS 3, and 3x and 4x are then part of the new MFG in DLSS 4.
Digital Foundry has actual measurements, so whether or not that matches your intuition is irrelevant. But I think the part you forgot is that generating the frames still takes time in and of itself, and you then need to still present those at a consistent rate for motion smoothness.
Watched their coverage, not much in the way of details that would explain why the (slightly) increased latency. Your speculation about why MFG takes longer makes sense to me, although I have troubles picturing how exactly the puzzle all fits together. Will have to wait for more in-depth coverage.
Seems like I misunderstood your notation.
> Digital Foundry has actual measurements, so whether or not that matches your intuition is irrelevant.
I mean, it's pretty relevant to me. Will watch it later then.
Yeah, in hindsight I should have figured it was more generated frames presented at a lower frame times (shorter period).
The Digital Foundry initial impressions are promising, but for me with a 144hz monitor that prefers V-Sync with an an FPS cap slightly below, I'm not sure using 3x or 4x mode will be desirable with such a setup, since that would seemingly make your input lag comparable to 30fps. It seems like these modes are best used when you have extremely high refresh rate monitors (pushing 240hz+).
This is true, but it's worth noting that 3x was 5ms additional latency beyond original FG and 7ms for 4x, so the difference in latency between DLSS 3 FG and DLSS 4 MFG is probably imperceptible for most people.
I just saw the Digital Foundry results, and that's honestly really good.
I'm guessing users will self tune to use 2x/3x/4x based on their v-sync preference then.
yeah but it means MFG still has the same fundamental problem of FG that the latency hit is the largest in the only scenario where it's meaningfully useful. That is, at low 15-45fps native FPS, then the additional impact of an additional frame of buffering combined with the low initial FPS means the latency hit is relatively huge.
So Nvidia's example of taking cyberpunk from 28fps to 200+ or whatever doesn't actually work. It'll still feel like 20fps sluggish watery responses even though it'll look smooth
> It’s 3 extrapolated frames not interpolated. So would be reduced lag at the expense of greater pop-in.
it's certainly not reduced lag relative to native rendering. It might be reduced relative to dlss3 frame gen though.
This isn't relevant to what I said?
Add Nvidia reflex 2 to it and it is.
> It’s 3 extrapolated frames not interpolated.
Do you have a source for this? Doesn't sound like a very good idea. Nor do I think there's additional latency mind you, but not because it's not interpolation.
Interpolation means you have frame 1 and frame 2, now compute the interstitial steps between these two.
Extrapolation means you have frame 1, and sometime in the future you'll get a frame 2. But until then, take the training data and the current frame and "guess" what the next few frames will be.
Interpolation requires you to have the final state between the added frames, extrapolation means you don't yet know what the final state will be but you'll keep drawing until you get there.
You shouldn't get additional latency from generating, assuming it's not slowing down the traditional render generation pipeline.
I understand this - doesn't address anything of what I said.
What if you used the last two frames instead of just one.. then it's pretty much same thing
This is not even about the same technology the person I replied to was talking about in the quoted section (this is Reflex 2, not MFG).
Could you please point out where on that page does it say anything about "extrapolation"? Searched for the (beginning of the) word directly and even gave all the text a skim, didn't catch anything of the sort.
The literal word doesn't have to be there in order to imply that it were extrapolation instead of interpolation. By your logic, there is no implication of interpolation versus extrapolation either. Nvidia simply won't use such terms, I believe.
They did specify [0] that it was intermediate frames they were generating back when the 1st version frame generation was announced with DLSS 3, which does translate to interpolation. It's only natural to assume MFG is the same, just with more than a single intermediate frame being generated.
It is also just plain unsound to think that it'd not be interpolation - extrapolating frames into the future means inevitably that future not coming to be, and there being serious artifacts every couple frames. This is just nonsense.
I checked through (the autogenerated subtitles of) the entire keynote as well, zero mentions there either. I did catch Linus from Linus Tech Tips saying "extrapolation" in his coverage [1], but that was clearly meant colloquially. Maybe that's where OP was coming from?
I will give you that they seem to intentionally avoid the word interpolation, and it is reasonable to think then that they'd avoid the word extrapolation too. But then, that's why I asked the person above. If they can point out where on that page I should look for a paragraph that supports what they were saying, not with a literal mention of the word but otherwise, it would be good to know.
[0] https://www.nvidia.com/en-us/geforce/news/dlss3-ai-powered-n...
MFG is almost certainly still interpolation. I'm guessing Reflex 2 is more akin to extrapolation, and might be getting the media to cross wires?
Reflex 2 seems to be asynchronous projection [0]. How the two techs come together when both are enabled, I'm not quite sure how to fit together in my head, but clearly it works fine at least. Hopefully there will be more coverage about these later.
Jensen Huang said during his keynote that you get 3 AI generated frames when rendering a native frame.
This doesn't imply "extrapolation" instead of interpolation.
That does imply extrapolation since interpolation requires 2 frames and they are only using 1.
It does imply extrapolation but I'm hearing doesn't actually provide it and they actually interpolate.
Which fits with them having same latency.. have to wait for that next frame.
I'm hearing it's actually interpolated frames, not extrapolated.. I would like better confirmation of that though.
Yeah I’m not holding my breath if they aren’t advertising it.
I’m expecting a minor bump that will look less impressive if you compare it to watts, these things are hungry.
It’s hard to get excited when most of the gains will be limited to a few new showcase AAA releases and maybe an update to a couple of your favourites if your lucky.
It feels like GPUs are now well beyond what game studios can put out. Consoles are stuck at something like RTX 2070 levels for some years still. I hope Nvidia puts out some budget cards for 50 series
At the same time they’re still behind demand as most of the pretty advertising screenshots and frame rate bragging have been behind increasingly aggressive upscaling.
On pc you can turn down the fancy settings at least but For consoles I wonder if we’re now in the smudgy upscale era like overdone bloom or everything being brown.
Like with how you cannot distinguish reality from CGI in movies DLSS will also become perfected over the years.
I guess to everyone with working eyes this means DLSS will never be perfect. I agree.
I have trained transformers on a 4090 (not language models). Here’s a few notes.
You can try out pretty much all GPUs on a cloud provider these days. Do it.
VRAM is important for maxing out your batch size. It might make your training go faster, but other hardware matters too.
How much having more VRAM speeds things up also depends on your training code. If your next batch isn’t ready by the time one is finished training, fix that first.
Coil whine is noticeable on my machine. I can hear when the model is training/next batch is loading.
Don’t bother with the founder’s edition.
Thanks for sharing your insights, was thinking of upgrading to a 5090 partially to dabble with NNs.
> Don’t bother with the founder’s edition.
Why?
When I bought mine the FE was $500 more. Only reason to get it is better cooling and size which were not factors for me.
Ah, hadn't been paying that much attention. Thought I had seen them at roughly equal pricing but at $500 extra yeah no thanks.
It's a shame to see they max out at just 32GB, for that price in 2025 you'd be hoping for a lot more, especially with Apple Silicon - while not nearly as fast - being very usable with 128GB+ for LLMs for $6-7k USD (comes with a free laptop too ;))
Apple Silicons architecture is better for running huge AI models but much worse for just about anything else that you'd want to run on a GPU, bandwidth is far more important in most other applications.
That's not even close, the M4 Max 12C has less than a third of the 5090s memory throughput and the 10C version has less than a quarter. The M4 Ultra should trade blows with the 4090 but it'll still fall well short of the 5090.
- [deleted]
Presumably the workstation version will have 64GB of VRAM.
By the way, this is even better as far as memory size is concerned:
https://www.asrockrack.com/minisite/AmpereAltraFamily/
However, memory bandwidth is what matters for token generation. The memory bandwidth of this is only 204.8GB/sec if I understand correctly. Apple's top level hardware reportedly does 800GB/sec.
AMD Strix Halo is 256GB/sec or so. Similarly AMD's Epyc Sienna family is similar. The EPYC turin family (zen 5) has 576GB/sec or so per socket. Not sure how well any of them do on LLMs. Bandwidth helps, but so does hardware support for FP8 or FP4.
Memory bandwidth is the most important thing for token generation. Hardware support for FP8 or FP4 probably does not matter much for token generation. You should be able to run the operations on the CPU in FP32 while reading/writing them from/to memory as FP4/FP8 by doing conversions in the CPU's registers (although to be honest, I have not looked into how those conversions would work). That is how llama.cpp supports BF16 on CPUs that have no BF16 support. Prompt processing would benefit from hardware FP4/FP8 support, since prompt processing is compute bound, not memory bandwidth bound.
As for how well those CPUs do with LLMs. The token generation will be close to model size / memory bandwidth. At least, that is what I have learned from local experiments:
https://github.com/ryao/llama3.c
Note that prompt processing is the phase where the LLM is reading the conversation history and token generation is the phase where the LLM is writing a response.
By the way, you can get an ampere altra motherboard + CPU for $1,434.99:
https://www.newegg.com/asrock-rack-altrad8ud-1l2t-q64-22-amp...
I would be shocked if you can get any EYPC CPU with similar/better memory bandwidth for anything close to that price. As for Strix Halo, anyone doing local inference would love it if it is priced like a gaming part. 4 of them could run llama 3.1 405B on paper. I look forward to seeing its pricing.
Hmm, seems pretty close. Not sure how the memory channels related to the performance. But the ampere board above has 8 64 bit channels @ 3200 MHz, the AMD Turins have 24 32 bit channels @ 6400 Mhz. So the AMD memory system is 50% wider, 2x the clock, and 3x the channels.
As for price the AMD Epyc Turin 9115 is $726 and a common supermicro motherboard is $750. Both the Ampere and AMD motherboards have 2x10G. No idea if the AMD's 16 cores with Zen 5 will be able to saturate the memory bus compared to 64 cores of the Amphere Altra.
I do hope the AMD Strix Halo is reasonably priced (256 bits wide @ 8533 MHz), but if not the Nvidia Digit (GB10) looks promising. 128GB ram, likely a wider memory system, and 1 Pflop of FP4 sparse. It's going to be $3k, but with 128GB ram that is approaching reasonable. Seems like it's likely has around 500GB/sec of memory bandwidth, but that is speculation.
Interesting Ampere board, thanks for the link.
All of this is true only while no software is utilizing parallel inference of multiple LLM queries. The Macs will hit the wall.
People interested in running multiple LLM queries in parallel are not people who would consider buying Apple Silicon.
There are other ways to parallelize even a single query for faster output, e.g. speculative decoding with small draft models.
- [deleted]
Just isn't comparable speed wise for anything apart from LLM and in the long run you can double up and swap out Nvidia cards while Mac you need to rebuy the whole machine.
Guess you missed the Project Digits announcement... desktop supercomputer for AI at $3k (128 GB ram)
Ooo, that means its probably time for me to get a used 2080, or maybe even a 3080 if I'm feeling special
The 2080 was a particularly poor value card, especially when considering the small performance uplift and the absolute glut of 1080 Tis that were available. A quick look on my local ebay also indicates they're both around the €200-250 range for used buy it now, so it seems to make way more sense to go to a 3080.
2080 TI though is a really good sweet spot for price/performance.
Why not go for AMD? I just got a 7900XTX for 850 euros, it runs ollama or comfyUI via WSl2 quite nicely.
AMD is an excellent choice. NVidia UI has been horrible and AMD adrenaline has been better than NVidia for several years now. With NVidia, you are paying A LOT of extra money for trickery and fake pixels, fake frames, fake (ai) rendeering. All fakeness. All hype. When you get down to the raw performance of these new cards, it must be a huge disappointment, otherwise, why would Jensen completely forget to mention anything REAL about the performance of these cards? These are cut-down cards designed to sell at cut-down prices with lots of fluff and whipped cream added on top ...
Do you have a good resource for learning what kinds of hardware can run what kinds of models locally? Benchmarks, etc?
I'm also trying to tie together different hardware specs to model performance, whether that's training or inference. Like how does memory, VRAM, memory bandwidth, GPU cores, etc. all play into this. Know of any good resources? Oddly enough I might be best off asking an LLM.
I tested ollama with 7600XT at work and the mentioned 7900XTX. Both run fine with their VRAM limitations. So you can just switch between different quantization of llama 3.1 or the vast amount of different models at https://ollama.com/search
To prevent custom implementations is recommended to get a Nvidia card. Minimum 3080 to get some results. But if you want video you should go for either 4090 or 5090. ComfUI is a popular interface which you can use for graphical stuff. Images and videos. Local text models I would recommend to use the Misty app. Basically a wrapper and downloader for various models. Tons of youtube videos on how to achieve stuff.
DLSS is good and keeps improving, as with DLSS 4 where most of the features are compatible with even the 2000 series cards. AMD does not have the same software feature set to justify a purchase.
AMD driver quality is crap. I upgraded from GTX 1080 to RX 6950 XT because I found a good deal and I didn't want to support nvidia's scammy bullshit of launching inferior GPUs under the same names. Decided to go with AMD this time, and I had everything: black screens, resolution drops to 1024x768, total freezes, severe lags in some games (BG3) unless I downgrade the driver to a very specific version.
It is an outdated claim.
I have both 4090 (workstation) and 7900XT (to play some games) and I would say that 7900XT was rock solid for me for the last year (I purchased it in Dec 2023).
You assume that. I wish it was. This is my actual recent experience with AMD and their drivers. It did get better in the past few months, but I still occasionally get total freezes when only a hard reset helps.It is an outdated claim.Good for you though.
Pointless putting yourself through the support headaches or having to wait for support to arrive to save a few dollars because the rest of the community is running Nvidia
Nah it's quite easy these days. Ollama runs perfectly fine on Windows, comfyUI still has some not ported requirements, so you have to do stuff through WSL2.
a 4070 has much better performance for much cheaper than a 3080...
Any the 4070 Super is relatively available too. I just bought one with only a small amount of hunting. Bought it right off of Best Buy, originally tried going to the Microcenter near my parent's house while I was down there but should have bought the card online for pickup. In the 2 days between my first check and arriving at the store ~20 cards sold.
What was the drop in 3070 pricing when the 4070 was released? We should expect a similar drop now I suppose?
It took a while according to the first price chart I found. The initial release of the 4070 Ti/FE in Jan 2023 didn't move the price much but the later release did start dropping the price. Nvidia cards are pretty scarce early in the generation so the price effect takes a minute to really kick into full force.
I just upgraded from a 2080 Ti I had gotten just a few weeks into the earliest COVID lockdowns because I was tired of waiting constantly for the next generation.
https://howmuch.one/product/average-nvidia-geforce-rtx-3070-...
The interesting part to me was that Nvidia claim the new 5070 will have 4090 level performance for a much lower price ($549). Less memory however.
If that holds up in the benchmarks, this is a nice jump for a generation. I agree with others that more memory would've been nice, but it's clear Nvidia are trying to segment their SKUs into AI and non-AI models and using RAM to do it.
That might not be such a bad outcome if it means gamers can actually buy GPUs without them being instantly bought by robots like the peak crypto mining era.
That claim is with a heavy asterisk of using DLSS4. Without DLSS4, it’s looking to be a 1.2-1.3x jump over the 4070.
Do games need to implement something on their side to get DLSS4?
The asterisk is DLSS4 is using AI to generate extra frames, rather than rendering extra frames, which hurts image stability and leads to annoying fuzziness/flickering. So it's not comparing like with like.
Also since they're not coming from the game engine, they don't actually react as the game would, so they don't have advantages in terms of response times that actual frame rate does.
On the contrary, they need to be optimized so badly that they run like shit on 2025 graphics cards despite looking the exact same as games from years ago
Was surprised to relearn the GTX 980 premiered at $549 a decade ago.
Which is 750$ in 2024 adjusted for inflation and you got a card that's providing 1/3 of performance of a 4070Ti at equal price range. 1/4 with 5070Ti probably.
3x the FPS at same cost (ignoring AI cores, encoders, resolutions, etc.) is a decent performance track record. With DLSS enabled the difference is significantly bigger.
As a lifelong nvidia consumer, I think it's a safe bet to ride out the first wave of 5xxx series GPUs and wait for the inevitable 5080/5070 (GT/Ti/Super/whatever) that should release a few months after with similar specs and better performance based on whatever the complaints surrounding the initial GPUs lacked.
I would expect something like the 5080 super will have something like 20/24Gb of VRAM. 16Gb just seems wrong for their "target" consumer GPU.
Or you wait out the 5000 Super too and get the 6000 series that fixes all the first-gen 5000-Super problems...
They could have used 32Gbps GDDR7 to push memory bandwidth on the 5090 to 2.0TB/sec. Instead, they left some performance on the table. I wonder if they have some compute cores disabled too. They are likely leaving room for a 5090 Ti follow-up.
Maybe they wanted some thermal/power headroom. It's already pretty mad.
I made the mistake of not waiting befpre.
This time around, I will save for the 5090 or just wait for the Ti/Super refreshes.
A few months? Didn't the 4080 Super release at least a few years after the 4080?
Any advice on how to buy the founders edition when it launches, possibly from folks who bought the 4090 FE last time around? I have a feeling there will be a lot of demand.
Getting a 3080 FE (I also had the option to get the 3090 FE) at the height of pandemic demand required me sleeping outside a Best Buy with 50 other random souls on a wednesday night.
At that time I ended up just buying a gaming PC packaged with the card. I find it's generally worth it to upgrade all the components of the system along with the GPU every 3 years or so.
This goes at a significant premium for on average OEM parts that are subpar. Buying individually yields much better results and these days it's less of a hassle than it used to.
It was likely from an integrator not a huge OEM that's spinning their own proprietary motherboard designs like Dell. In that case they only really paid the integrator's margin and lost the choice of their own parts.
Do you live somewhat near a Microcenter? They'll likely have these as in-store pick up only, no online reservations, 1 per customer. Recently got a 9800X3D CPU from them, its nice they're trying to prevent scalping.
I do! Great advice. Going off on a tangent, when I recently visited my Microcenter after a few years of not going there, it totally gave me 80s vibes and I loved it. Staff fit the "computer nerd" stereotype accurately, including jeans shirts and ponytails. And best of all they actually wanted to talk to me and help me find stuff, and were knowledgeable.
Ours just opened in 2024 and I've tried to give them as much business as possible. Ordering everything for a new PC build, sans the AMD CPU, and then doing pick up was a breeze. Feels great that the place is completely packed every time I go in there. I feel like Bestbuy made me sort of hate electronics retail and Microcenter is reminding of what it used to be like going to Radio Shack and Compusa back in their hayday.
I had a similar feeling when going to microcenter for the first time in years a few years ago, but in my case, it was a 90s vibe since I had first visited a computer store in the 90s.
As someone living (near) Seattle, this is a major issue for me every product launch and I don't have a solution.
The area's geography just isn't conducive to allowing a single brick and mortar store to survive and compete with online retail for costs vs volume; but without a B&M store there's no good way to do physical presence anti-scalper tactics.
I can't even get in a purchase opportunity lottery since AMD / Nvidia don't do that sort of thing for allocating restock quota tickets that could be used as tokens to restock product if a purchase is to the correct shipping address.
There is a Discord that sends notifications for stock drops. They are also on X.
* MegaGeometry (APIs to allow Nanite-like systems for raytracing) - super awesome, I'm super super excited to add this to my existing Nanite-like system, finally allows RT lighting with high density geometry
* Neural texture stuff - also super exciting, big advancement in rendering, I see this being used a lot (and helps to make up for the meh vram blackwell has)
* Neural material stuff - might be neat, Unreal strata materials will like this, but going to be a while until it gets a good amount of adoption
* Neural shader stuff in general - who knows, we'll see how it pans out
* DLSS upscaling/denoising improvements (all GPUs) - Great! More stable upscaling and denoising is very much welcome
* DLSS framegen and reflex improvements - bleh, ok I guess, reflex especially is going to be very niche
* Hardware itself - lower end a lot cheaper than I expected! Memory bandwidth and VRAM is meh, but the perf itself seems good, newer cores, better SER, good stuff for the most part!
Note that the material/texture/BVH/denoising stuff is all research papers nvidia and others have put out over the last few years, just finally getting production-ized. Neural textures and nanite-like RT is stuff I've been hyped for the past ~2 years.
I'm very tempted to upgrade my 3080 (that I bought used for $600 ~2 years ago) to a 5070 ti.
For gaming I'm also looking forward to the improved AI workload sharing mentioned, where, IIUC, AI and graphics workloads could operate at the same time.
I'm hoping generative AI models can be used to generate more immersive NPCs.
- [deleted]
I have a feeling regular consumers will have trouble buying 5090s.
RTX 5090: 32 GB GDDR7, ~1.8 TB/s bandwidth. H100 (SXM5): 80 GB HBM3, ~3+ TB/s bandwidth.
RTX 5090: ~318 TFLOPS in ray tracing, ~3,352 AI TOPS. H100: Optimized for matrix and tensor computations, with ~1,000 TFLOPS for AI workloads (using Tensor Cores).
RTX 5090: 575W, higher for enthusiast-class performance. H100 (PCIe): 350W, efficient for data centers.
RTX 5090: Expected MSRP ~$2,000 (consumer pricing). H100: Pricing starts at ~$15,000–$30,000+ per unit.
H100 has 3958 TFLOPS sparse fp8 compute. I’m pretty sure listed tflops for 5090 are sparse (and probably) fp4/int4.
Yes, that's the case. Check the (partial) spec of 5090 D, which is the nerfed version for export to China. It is marketed as having 2375 "AI TOPS".
BIS demands it to be less than $4800 TOPS \times Bit-Width$, and the most plausible explanation for the number is - 2375 sparse fp4/int4 TOPS, which means 1187.5 dense TOPS for 4 bit, or $4750 TOPS \times Bit-Width$.
And just for the context RTX 4090 has 2642 sparse int4 TOPS, so it’s about 25% increase
How well do these models do at parallelizing across multiple GPUs? Is spending $4k on the 5090 a good idea for training, slightly better performance for much cheaper? Or a bad idea, 0x as good performance because you can’t fit your 60GB model on the thing?
> regular consumers will have trouble buying 5090s.
They’re not really supposed to either judging by how they priced this. For non AI uses the 5080 is infinitely better positioned
> For non AI uses the 5080 is infinitely better positioned
...and also slower than a 4090. Only the 5090 got a gen/gen upgrade in shader counts. Will have to wait for benchmarks of course, but the rest of the 5xxx lineup looks like a dud
You’re comparing different price classes. New 5080 is 999 usd. Even secondhand 4090s from questionable eBay sellers are substantially more
That's my worry too, I'd like one or two, but 1) will either never be in line for them 2) or can only find via secondary market at 3 or 4x the price...
Anyone has any info on Node? Can't find anything online. Seems to be 4nm but performance suggest otherwise. Hopefully someone do a deep dive soon.
Good bet it's 4nm. The 5090 doesn't seem that much greater than the 4090 in terms of raw performance. And it has a big TDP bump to provide that performance.
TSMC 4NP process
Source: https://www.nvidia.com/en-us/data-center/technologies/blackw...
I'm guessing it's N4 and the performance is coming from larger dies and higher power.
Does any game need 32gb VRAM. Did they even use the full 24Gb of the 4090s?
It seems obvious to me that even NVIDIA knows that 5090s and 4090s are used more for AI Workloads than gaming. In my company, every PC has 2 4090s, and 48GB is not enough. 64GB is much better, though I would have preferred if NVIDIA went all in and gave us a 48GB GPU, so that we could have 96GB workstations at this price point without having to spend 6k on an A6000.
Overall I think 5090 is a good addition to the quick experimentation for deep learning market, where all serious training and inference will occur on cloud GPU clusters, but we can still do some experimentation on local compute with the 5090.
Way too little memory. :(
Can anyone suggest a reliable way to procure a GPU at launch (in the EU)?
I always end up late to the party and the prices end up being massively inflated - even now I cant seem to buy a 4090 for anywhere close to the RRP.
575W TDP for the 5090. A buddy has 3x 4090 in a machine with a 32 core AMD cpu must be putting out close to 2000W of heat at peak if he switched to 5090. Uff
I have a very similar setup, 3x4090s. Depending on the model I’m training, the GPUs use anywhere from 100-400 watts, but don’t get much slower when power limited to say, 250w. So they could power limit the 5090s if they want and get pretty decent performance most likely.
The cat loves laying/basking on it when it’s putting out 1400w in 400w mode though, so I leave it turned up most of the time! (200w for the cpu)
May I ask what you’re training? And why not just rent GPUs in some cloud?
According to Weights & Biases, my personal, not work related account was in the top 5% of users, and I trained models for a total of nearly 5000 hours - so if I rented equivalent compute to this machine, I’d probably be out 5-10k so far - so this machine is very close to paying for itself if it already hasn’t.
Also, not having to do the environment setup typically required for cloud stuff is a nice bonus.
2kW is literally the output of my patio heater haha
They work as effective heaters! I haven’t used my (electric) heat all winter, I just use my training computer’s waste heat instead.
You also need to upgrade your air conditioner
Yeah I'm not really sure what the solution is at this point. Put it in my basement and run 50foot HDMI cables through my house or something...
Or just open a window, depending on where you live
One thing I always remember when people say a 2k gpu is insanity. How many people get a 2k ebike. a 100k weekend car. a 15k motorcycle to use once a month. a time share home. Comparatively a gamer using it even a few hours a day for 3k 4090 build is really an amazing return on that investment.
Correct, people balk at high GPU prices when others have expensive hobbies too. I think it's because people expect GPUs and PC components to be democratized whereas an expensive car or motorcycle to not be. 5090s are absolutely luxury purchases, no one "needs" one; treat it the same as a sportscar in terms of the clientele able to buy it.
Some of the better video generators with pretty good quality can run on the 32gb version. Expect lots of AI generated videos with this generation of videocards. Price is steep and we need another 9700 ati successtory for some serious nvidia competition. Not going to happen anytime soon I am afraid.
interesting launch but vague in its own way like the one from AMD (less so but in a different way).
it is easy to be carried away with vram size, but keeping in mind that most people with apple silicon (who can enjoy several times more memory) are stuck at inference, while training performance is off the charts through cuda hardware.
the jury is yet to be out on actual ai training performance, but i bet 4090, if sold at 1k or below, would be better value than lower tier 50 series. the "ai tops" of the 50 series is only impressive for the top model, while the rest are either similar or with lower memory bandwidth despite the newer architecture.
i think by now the training is best left on the cloud and overall i'd be happy rather owning a 5070 ti at this rate.
Would have been nice to get double the memory on the 5090 to run those giant models locally. Would've probably upgraded at 64gb but the jump from 24 to 32gb isn't big enough
Gaming performance has been plateaued for some time now, maybe an 8k monitor wave can revive things
Smaller cards with higher power consumption – will GPU water-cooling be cool again?
The most interesting aspect here might be the improved tensor cores for AI workloads - could finally make local LLM inference practical for developers without requiring multiple GPUs.
Mmm i think my wallet Is safe since i only play SNES and old dos games.
- [deleted]
AI is going to push the price closer to $3000. See what happened with crypto a couple of years back.
The ~2017 crypto rush told Nvidia how much people were willing to spend on GPUs, so they priced their next series (RTX 2000) much higher. 2020 came around, wash, rinse, repeat.
Note the 20 series bombed, largely because of the price hikes coupled with meager performance gains, so the initial plan was for the 30 series to be much cheaper. But then the 30 series scalping happened and they got a second go at re-anchoring what people thought of as reasonable GPU prices. Also they have diversified other options if gamers won't pay up, compared to just hoping that GPU-minable coins won over those that needed ASICs and the crypto market stayed hot. I can see nVidia being more willing to hurt their gaming market for AI than they ever were for crypto.
Also also, AMD has pretty much thrown in the towel at competing for high end gaming GPUs already.
Official release: https://nvidianews.nvidia.com/news/nvidia-blackwell-geforce-...
This thread was posted first.
- [deleted]
Finally I will be able to run Cities Skylines 2 at 60fps!
GPU stands for graphics prediction unit these days
- [deleted]
Meh. Feels like astronomical prices for the smallest upgrades they could get away with.
I miss when high-end GPUs were $300-400, and you could get something reasonable for $100-200. I guess that's just integrated graphics these days.
The most I've ever spent on a GPU is ~$300, and I don't really see that changing anytime soon, so it'll be a long time before I'll even consider one of these cards.
Intel ARC B580 is $249 MSRP and right up your alley in that case.
Yep. If I needed a new GPU, that's what I'd go for. I'm pretty happy with what I have for the moment, though.
I'd go for the A770 over the B580. 16GB > 12GB, and that makes a difference for a lot of AI workloads.
An older 3060 12GB is also a better option than the B580. It runs around $280, and has much better compatibility (and, likely, better performance).
What I'd love to see on all of these are specs on idle power. I don't mind the 5090 approaching a gigawatt peak, but I want to know what it's doing the rest of the time sitting under my desk when I just have a few windows open and am typing a document.
A gigawatt?! Just a little more power and I won't need a DeLorean for time travel!
>I miss when high-end GPUs were $300-400, and you could get something reasonable for $100-200.
That time is 25 years ago though, i think the Geforce DDR is the last high end card to fit this price bracket. While cards have gotten a lot more expensive those $300 high end cards should be around $600 now. And $200-400 for low end still exists.
2008 is 25 years ago?
I'm really disappointed in all the advancement in frame generation. Game devs will end up relying on it for any decent performance in lieu of actually optimizing anything, which means games will look great and play terribly. It will be 300 fake fps and 30 real fps. Throw latency out the window.
This is an odd take I keep hearing, ANY performance increase you could argue that game devs will rely upon it for decent performance.
It doesn't matter if that's through software or hardware improvements.
More fake poor frames at less price
It looks like the new cards are NO FASTER than the old cards. So they are hyping the fake frames, fake pixels, fake AI rendering. Anything fake = good, anything real = bad.
This is the same thing they did with the RTX 4000 series. More fake frames, less GPU horsepower, "Moore's Law is Dead", Jensen wrings his hands, "Nothing I can do! Moore's Law is Dead!" which is how Intel has been slacking since 2013.
Its more like the 20 series. Definitely faster and for me worth the upgrade. I just count the transistors for a reference. 92 and 77 billion. So yeah not that much.
Everything is fake these days. We have mass psychosis...everyone is living in a collective schizophrenic delusion
Do they come with a mini nuclear reactor to power them?
No, you get that from Enron.
The future is SMRs next to everyone's home
Did they discontinue Titan series for good?
Last titan was released 2018.... 7 years ago.
They may resurrect it at some stage, but at this stage yes.
The 3090, 3090 Ti, 4090 and 5090 are Titan series cards. They are just no longer labelled Titan.
Yes the xx90 is the new Titan
Somewhat related, any recommendations for 'pc builders' where you can configure a PC with the hardware you want, but have it assembled and shipped to you instead of having to build it yourself? With shipping to Canada ideally.
I'm planning to upgrade (prob to a mid-end) as my 5 year old computer is starting to show it's age, and with the new GPUs releasing this might be a good time.
I don't know of any such service, but I'm curious what the value is for you? IMO picking the parts is a lot harder than putting them together.
Typically you get warranty on the whole thing through a single merchant, so if anything goes wrong you don't have to deal with the individual parts manufacturers.
Memoryexpress has a system builder tool.
Puget Systems is worth checking out.
{kind=link}
{kind=link}
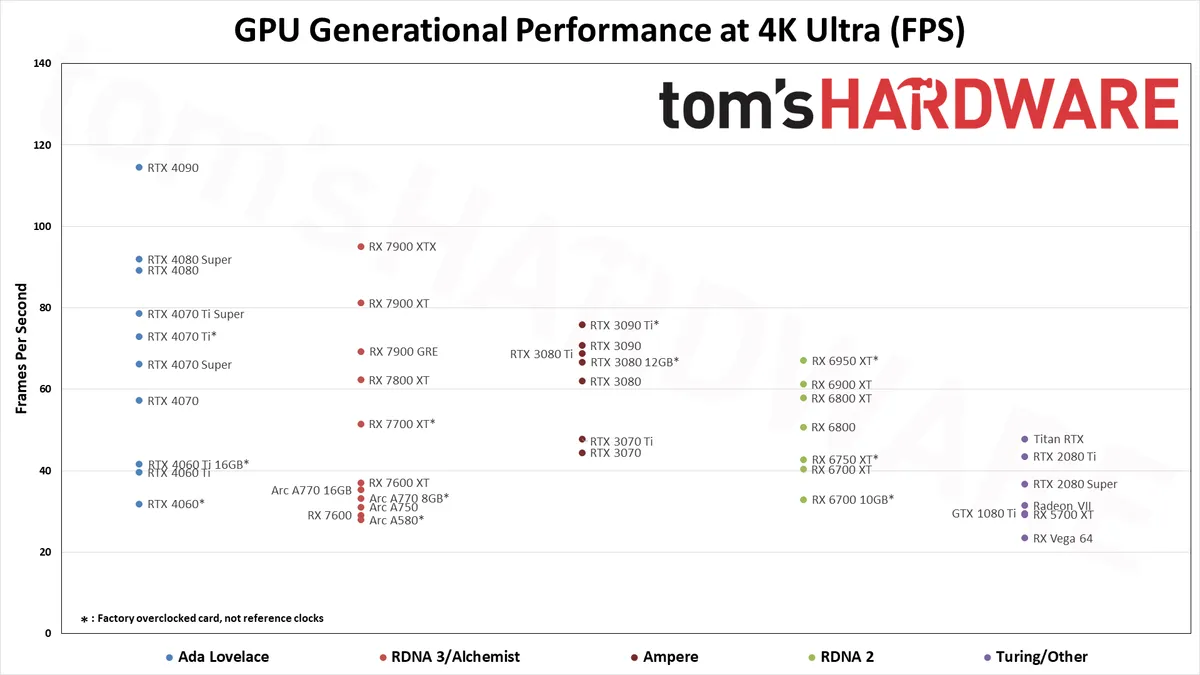{kind=link}
{kind=link}
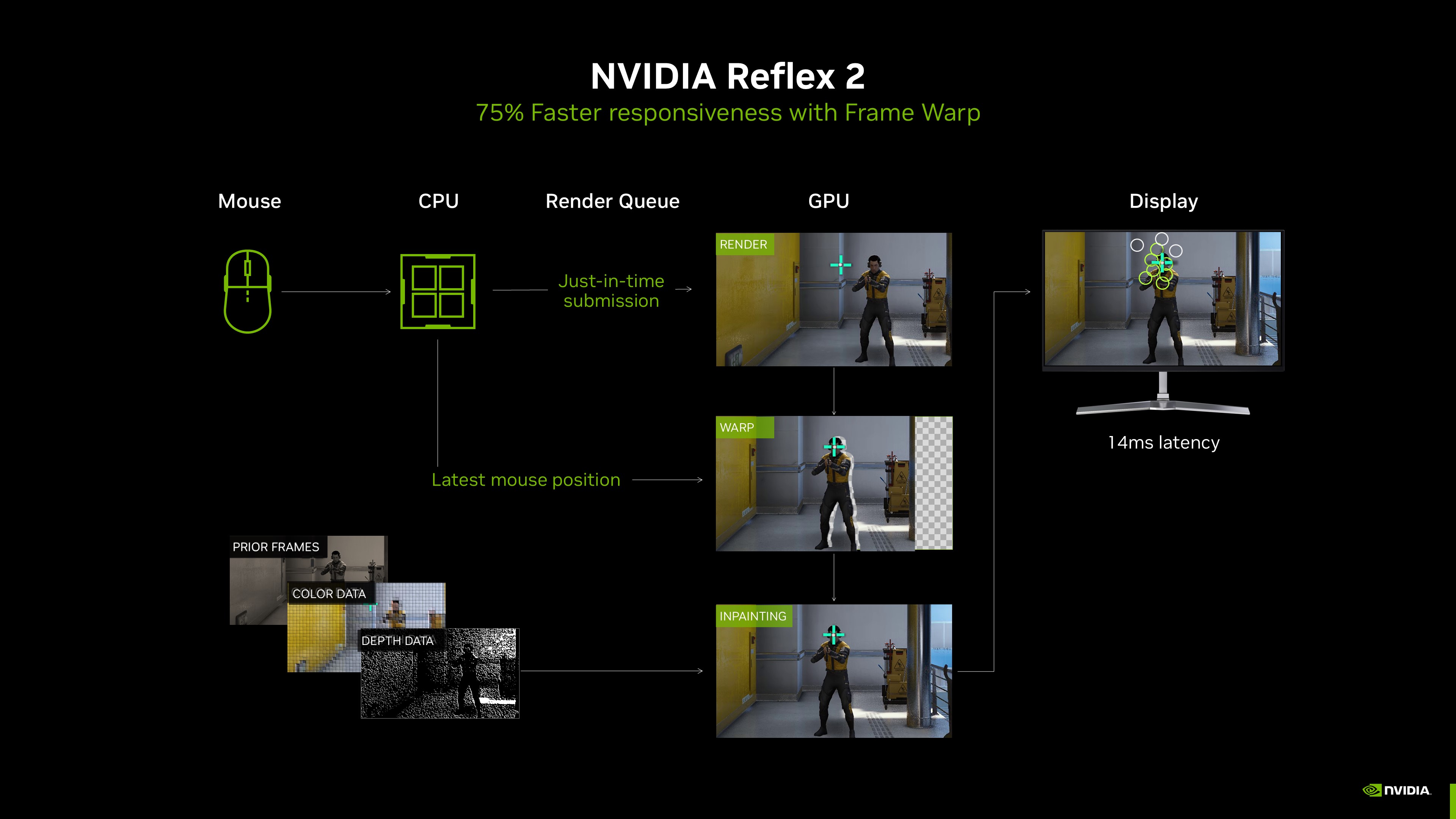{kind=link}