I'm currently making 2bit to 8bit GGUFs for local deployment! Will be up in an hour or so at https://huggingface.co/unsloth/Qwen3-Coder-480B-A35B-Instruc...
Also docs on running it in a 24GB GPU + 128 to 256GB of RAM here: https://docs.unsloth.ai/basics/qwen3-coder
Looks like the docs have a typo:
That should be recommended token output, as shown in the official docs as:Recommended context: 65,536 tokens (can be increased)Adequate Output Length: We recommend using an output length of 65,536 tokens for most queries, which is adequate for instruct models.Oh thanks - so the output can be any length you like - I'm actually also making 1 million context length GGUFs as well! https://huggingface.co/unsloth/Qwen3-Coder-480B-A35B-Instruc...
Do 2bit quantizations really work? All the ones I've seen/tried were completely broken even when 4bit+ quantizations worked perfectly. Even if it works for these extremely large models, is it really much better than using something slightly smaller on 4 or 5 bit quant?
Oh the Unsloth dynamic ones are not 2bit at all - it's a mixture of 2, 3, 4, 5, 6 and sometimes 8bit.
Important layers are in 8bit, 6bit. Less important ones are left in 2bit! I talk more about it here: https://docs.unsloth.ai/basics/unsloth-dynamic-2.0-ggufs
Not an AI researcher here so this is probably common knowledge for people in this field, but I saw a video about the quantization recently and wondered exactly about that, if it's possible to compress a net by using more precision where it counts and less precision where it's not important. And also wondered how one would go about deciding which parts count and which don't
Great to know that this is already a thing and I assume model "compression" is going to be the next hot topic
Yes you're exactly thinking correctly! We shouldn't quantize a model naively to 2bit or 4bit, but we should do it smartly!
How do you pick which one should be 2, which one should be 4, etc. Is this secret sauce? or, something open?
Oh I wrote about it here: https://docs.unsloth.ai/basics/unsloth-dynamic-2.0-ggufs We might provide some scripts for them in the future!
Thanks! But, I can't find any details on how you "intelligently adjust quantization for every possible layer" from that page. I assume this is a secret?
I am wondering about the possibility that different use cases might require different "intelligent quantization", i.e., quantization for LLM for financial analysis might be different from LLM for code generation. I am currently doing a postdoc in this. Interested in doing research together?
Oh we haven't yet published about it yet! I talk about in bits and pieces - we might do a larger blog on it!
Yes different use cases will be different - oh interesting! Sorry I doubt I can be of much in our research - I'm mainly an engineering guy so less research focused!
How do you decide which layers are the important ones?
I wrote approximately in the blog about it and linked some papers! I also wrote about it here - https://unsloth.ai/blog/dynamic-4bit - one has to inspect the activation and weight quantization errors!
So you are basically looking at "fMRI" of the "brain" while it's doing a wide range of things and cutting out the things that stay dark the most?
Oh that's a good analogy! Yes that sounds right!
> The key reason to use Unsloth quants is because of our deep involvement in fixing critical bugs across major models
sounds convincing, eh ... /s
On the less cynical note, approach does look interesting but I'd also like to understand how and why does it work, if it works at all.
Oh we actually fixed bugs! We fixed a few bugs in Gemma - see https://news.ycombinator.com/item?id=39671146, a gradient accumulation bug see https://news.ycombinator.com/item?id=41859037, Phi bugs, Llama bugs and more! See https://unsloth.ai/blog/reintroducing for more details!
What does your approach with dynamics weights has to do with those bugs? All those bugs seem uncorrelated to the technique.
Oh apologies I got confused - it's because when we calculate our dynamic quants, we have to do it on the fixed model!
For example in Phi 3 for example, the end of sentence token was wrong - if we use this, then our quants would be calibrated incorrectly, since chatting with the model will use the actual correct token.
Another is Llama 4 - https://github.com/ggml-org/llama.cpp/pull/12889 in which I fixed a RoPE issue - if we didn't fix it first, then again the calibration process would be incorrect.
Ok, this then goes to say that your approach doesn't work without applying whatever fixes to the vanilla models. What I'm trying to understand is the approach itself. Why does it and how does it work?
Oh I wrote a bit about it in https://docs.unsloth.ai/basics/unsloth-dynamic-2.0-ggufs and https://unsloth.ai/blog/deepseekr1-dynamic if that helps!
If you don't mind divulging, what resources and time did it take to dynamically quantize Qwen3-Coder?
It takes a few hours to compute the imatrix on some calibration dataset since we use more than 1-3 million tokens of high quality data. Then we have to decide on which layers to quantize to higher bits or not, which takes more time. And the quantization creation also takes some hours. Uploading also takes some time as well! Overall 8 hours maybe minimum?
What cluster do you have to do the quantizing? I'm guessing you're not using a single machine with a 3090 in your garage.
Oh definitely not! I use some spot cloud instances!
But you can get one of these quantized models to run effectively on a 3090?
If so, I'd love detailed instructions.
The guide you posted earlier goes over my (and likely many others') head!
Oh yes definitely! Oh wait is the guide too long / wordy? This section https://docs.unsloth.ai/basics/qwen3-coder-how-to-run-locall... shows how to run it on a 3090
Kind of you to respond! Thanks!
I have pretty bad ADHD. And I've only run locally using kobold; dilettante at DIY AI.
So, yeah, I'm a bit lost in it.
Oh sorry - for Kobold - I think it uses llama.cpp behind the hood? I think Kobold has some guides on using custom GGUFs
Thanks Daniel. Do you recommend any resources showing the differences between different quantizations?
Oh our blog https://docs.unsloth.ai/basics/unsloth-dynamic-2.0-ggufs compares the accuracy differences for each different quantization method for Llama 4 Scout and also Gemma 3 27B - they should apply to other quants (like Qwen 3 Coder)
I had given up long time ago on self hosted transformer models for coding because the SOTA was definetly in favor of SaaS. This might just give me another try.
Would llama.cpp support multiple (rtx 3090, no nvlink hw bridge) GPUs over PCIe4? (Rest of the machine is 32 CPU cores, 256GB RAM)
How fast you run this model will strongly depend on if you have DDR4 or DDR5 ram.
You will be mostly using 1 of your 3090s. The other one will be basically doing nothing. You CAN put the MoE weights on the 2nd 3090, but it's not going to speed up inference much, like <5% speedup. As in, if you lack a GPU, you'd be looking at <1 token/sec speeds depending on how fast your CPU does flops, and if you have a single 3090 you'd be doing 10tokens/ec, but with 2 3090s you'll still just be doing maybe 11tok/sec. These numbers are made up, but you get the idea.
Qwen3 Coder 480B is 261GB for IQ4_XS, 276GB for Q4_K_XL, so you'll be putting all the expert weights in RAM. That's why your RAM bandwidth is your limiting factor. I hope you're running off a workstation with dual cpus and 12 sticks of DDR5 RAM per CPU, which allows you to have 24 channel DDR5 RAM.
1 CPU, DDR4 ram
How many channels of DDR4 ram? What speed is it running at? DDR4-3200?
The (approximate) equation for milliseconds per token, is:
Time for token generation = (number of params active in the model)*(quantization size in bits)/8 bits*[(percent of active params in common weights)/(memory bandwidth of GPU) + (percent of active params in experts)/(memory bandwidth of system RAM)].
This equation ignores prefill (prompt processing) time. This assumes the CPU and GPU is fast enough compute-wise to do the math, and the bottleneck is memory bandwidth (this is usually true).
So for example, if you are running Kimi K2 (32b active params per token, 74% of those params are experts, 26% of those params are common params/shared expert) at Q4 quantization (4 bits per param), and have a 3090 gpu (935GB/sec) and an AMD Epyc 9005 cpu with 12 channel DDR5-6400 (614GB/sec memory bandwidth), then:
Time for token generation = (32b params)*(4bits/param)/8 bits*[(26%)/(935 GB/s) + (74%)/(614GB/sec)] = 23.73 ms/token or ~42 tokens/sec. https://www.wolframalpha.com/input?i=1+sec+%2F+%2816GB+*+%5B...
Notice how this equation explains how the second 3090 is pretty much useless. If you load up the common weights on the first 3090 (which is standard procedure), then the 2nd 3090 is just "fast memory" for some expert weights. If the quantized model is 256GB (rough estimate, I don't know the model size off the top of my head), and common weights are 11GB (this is true for Kimi K2, I don't know if it's true for Qwen3, but this is a decent rough estimate), then you have 245GB of "expert" weights. Yes, this is generally the correct ratio for MoE models, Deepseek R1 included. If you put 24GB of that 245GB on your second 3090, you have 935GB/sec speed on... 24/245 or ~10% of each token. In my Kimi K2 example above, you start off with 18.08ms per token spent reading the model from RAM, so even if your 24GB on your GPU was infinitely fast, it would still take... about 16ms per token reading from RAM. Or in total about 22ms/token, or in total 45 tokens/sec. That's with an infinitely fast 2nd GPU, you get a speedup of merely 3 tokens/sec.
Inspired me to write this, since it seems like most people don't understand how fast models run:
https://unexcitedneurons.substack.com/p/how-to-calculate-hom...
Thank you for that writeup!
In my case it is a fairly old system I built from cheap eBay parts. Threadripper 3970X with 8x32GB dual channel 2666Mhz DDR4.
Oh yes llama.cpp's trick is it supports any hardware setup! It might be a bit slower, but it should function well!
Thanks for the uploads! Was reading through the Unsloth docs for Qwen3-Coder before I found the HN thread :)
What would be a reasonable throughput level to expect from running 8-bit or 16-bit versions on 8x H200 DGX systems?
Oh 8*H200 is nice - for llama.cpp definitely look at https://docs.unsloth.ai/basics/qwen3-coder-how-to-run-locall... - llama.cpp has a high throughput mode which should be helpful.
You should be able to get 40 to 50 tokens / s in the minimum. High throughput mode + a small draft model might get you 100 tokens / s generation
Thank you for your work, does the Qwen3-Coder offer significant advantage over Qwen2.5-coder for non-agentic tasks like just plain autocomplete and chat?
Oh it should be better, especially since the model was specifically designed for coding tasks! You can disable the tool calling parts of the model!
I've been reading about your dynamic quants, very cool. Does your library let me produce these, or only run them? I'm new to this stuff.
Thank you! Oh currently not sadly - we might publish some stuff on it in the future!
Would a version of this ever be possible to run on a machine with a 16GB gpu and 64gb RAM?
What will be the approx token/s prompt processing and generation speed with this setup on RTX 4090?
I also just made IQ1_M which needs 160GB! If you have 160-24 = 136 ish of RAM as well, then you should get 3 tokens to 5 ish per second.
If you don't have enough RAM, then < 1 token / s
Any idea if there is a way to run on 256gb ram + 16gb vram with usable performance, even if barely?
Yes! 3bit maybe 4bit can also fit! llama.cpp has MoE offloading so your GPU holds the active experts and non MoE layers, thus you only need 16GB to 24GB of VRAM! I wrote about how to do in this section: https://docs.unsloth.ai/basics/qwen3-coder#improving-generat...
awesome documentation, I'll try this. thank you!
Cool, thanks! I'd like to try it
It just got uploaded! I made some docs as well on how to run it at https://docs.unsloth.ai/basics/qwen3-coder
hello sir
hi!
> Qwen3-Coder is available in multiple sizes, but we’re excited to introduce its most powerful variant first
I'm most excited for the smaller sizes because I'm interested in locally-runnable models that can sometimes write passable code, and I think we're getting close. But since for the foreseeable future, I'll probably sometimes want to "call in" a bigger model that I can't realistically or affordably host on my own computer, I love having the option of high-quality open-weight models for this, and I also like the idea of "paying in" for the smaller open-weight models I play around with by renting access to their larger counterparts.
Congrats to the Qwen team on this release! I'm excited to try it out.
> I'm most excited for the smaller sizes because I'm interested in locally-runnable models that can sometimes write passable code, and I think we're getting close.
Likewise, I found that the regular Qwen3-30B-A3B worked pretty well on a pair of L4 GPUs (60 tokens/second, 48 GB of memory) which is good enough for on-prem use where cloud options aren't allowed, but I'd very much like a similar code specific model, because the tool calling in something like RooCode just didn't work with the regular model.
In those circumstances, it isn't really a comparison between cloud and on-prem, it's on-prem vs nothing.
30B-A3B works extremely well as a generalist chat model when you pair with scaffolding such as web search. It's fast (for me) using my workstation at home running a 5070 + 128GB of DDR4 3200 RAM @ ~28 tok/s. Love MoE models.
Sadly it falls short during real world coding usage, but fingers crossed that a similarly sized coder variant of Qwen 3 can fill in that gap for me.
This is my script for the Q4_K_XL version from unsloth at 45k context:
llama-server.exe --host 0.0.0.0 --no-webui --alias "Qwen3-30B-A3B-Q4_K_XL" --model "F:\models\unsloth\Qwen3-30B-A3B-128K-GGUF\Qwen3-30B-A3B-128K-UD-Q4_K_XL.gguf" --ctx-size 45000 --n-gpu-layers 99 --slots --metrics --batch-size 2048 --ubatch-size 2048 --temp 0.6 --top-p 0.95 --min-p 0 --presence-penalty 1.5 --repeat-penalty 1.1 --jinja --reasoning-format deepseek --cache-type-k q8_0 --cache-type-v q8_0 --flash-attn --no-mmap --threads 8 --cache-reuse 256 --override-tensor "blk\.([0-9][02468])\.ffn_._exps\.=CPU"
I love Qwen3-30B-A3B for translation and fixing up transcripts generated by automatic speech recognition models. It's not the most stylish translator (a bit literal), but it's generally better than the automatic translation features built into most apps, and it's much faster since there's no network latency.
It has also been helpful (when run locally, of course) for addressing questions-- good faith questions, not censorship tests to which I already know the answers-- about Chinese history and culture that the DeepSeek app's censorship is a little too conservative for. This is a really fun use case actually, asking models from different parts of the world to summarize and describe historical events and comparing the quality of their answers, their biases, etc. Qwen3-30B-A3B is fast enough that this can be as fun as playing with the big, commercial, online models, even if its answers are not equally detailed or accurate.
> good faith questions
yep, when you hire an immigrate software engineer, you don't ask them if Israel has a right to exist, or whether Vladivostok is part of china. Unless you are a DoD vendor which there won't be an interview anyway.
Give devstral a try, fp8 should fit in 48GB, it was surprisingly good for a 24B local model, w/ cline/roo. Handles itself well, doesn't get stuck much, most of the things work OK (considering the size ofc)
I did! I do think Mistral models are pretty okay, but even the 4-bit quantized version runs at about 16 tokens/second, more or less usable but a biiiig step down from the MoE options.
Might have to swap out Ollama for vLLM though and see how different things are.
> Might have to swap out Ollama for vLLM though and see how different things are.
Oh, that might be it. Using gguf is slower than say AWQ if you want 4bit, or fp8 if you want the best quality (especially on Ada arch that I think your GPUs are).
edit: vLLM is better for Tensor Parallel and also better for batched inference, some agentic stuff can do multiple queries in parallel. We run devstral fp8 on 2x A6000 (old, not even Ada) and even with marlin kernels we get ~35-40 t/s gen and 2-3k pp on a single session, with ~4 parallel sessions supported at full context. But in practice it can work with 6 people using it concurrently, as not all sessions get to the max context. You'd get 1/2 of that for 2x L4, but should see higher t/s in generation since you have Ada GPUs (native support for fp8).
Currently, the goal of everyone is creating one master model to rule them all, so we haven't seen too much specialization. I wonder how much more efficient smaller models could be if we created language specialized models.
It feels intuitively obvious (so maybe wrong?) that a 32B Java Coder would be far better at coding Java than a generalist 32B Coder.
I’ll fill the role to push back on your Java coder idea!
First, Java code tends to be written a certain way, and for certain goals and business domains.
Let’s say 90% of modern Java is a mix of: * students learning to program and writing algorithms * corporate legacy software from non-tech focused companies
If you want to build something that is uncommon in that subset, it will likely struggle due to a lack of training data. And if you wanted to build something like a game, the majority of your training data is going to be based on ancient versions of Java, back when game development was more common in Java.
Comparatively, including C in your training data gives you exposure to a whole separate set of domain data for training, like IoT devices, kernels, etc.
Including Go will likely include a lot more networking and infrastructure code than Java would have had, which means there is also more context to pull from in what networking services expect.
Code for those domains follow different patterns, but the concepts can still be useful in writing Java code.
Now, there may be a middle ground where you could have a model that is still general for many coding languages, but given extra data and fine-tuning focused on domain-specific Java things — like more of a “32B CorporateJava Coder” model — based around the very specific architecture of Spring. And you’d be willing to accept that model to fail at writing games in Java.
It’s interesting to think about for sure - but I do feel like domain-specific might be more useful than language-specific
Don't we also find with natural languages that focusing on training data from only a single language doesn't actually result in better writing in the target language, either?
jetbrains have done this with their mellum models that they use for autocompletion, https://ollama.com/JetBrains
fine tuned rather than created from scratch though.
Been using ggerganov’s llama vscode plugin with the smaller 2.5 models and it actually works super nice on a M3 Max
I'm on a m1 max with 64gb ram, but i never use this vscode plugin before. Should I try?
Is this the one? https://github.com/ggml-org/llama.vscode it sems to be built for code completion rather than outright agent mode
What languages do you work in? How much code do you keep? Do you end up using it as scaffolding and rewriting it, it leaving most of it as is?
Languages: JS/TS, C/C++, Shader Code, Some ESP Arduino code. Not counting all the boilerplate and CSS that I dont care about too much.
It very much reminds of tabbing autocomplete with IntelliSense step by step, but in a more diffusion-like way.
but my tool-set is a mixture of agentic and autocomplete, not 100% of each. I try to keep a clear focus of the architecture, and actually own the code by reading most of it, keeping straight the parts of the code the way i like.
small models can never match bigger models, the bigger models just know more and are smarter. the smaller models can get smarter, but as they do, the bigger models get smart too. HN is weird because at one point this was the location where I found the most technically folks, and now for LLM I find them at reddit. tons of folks are running huge models, get to researching and you will find out you can realistically host your own.
> small models can never match bigger models, the bigger models just know more and are smarter.
They don't need to match bigger models, though. They just need to be good enough for a specific task!
This is more obvious when you look at the things language models are best at, like translation. You just don't need a super huge model for translation, and in fact you might sometimes prefer a smaller one because being able to do something in real-time, or being able to run on a mobile device, is more important than marginal accuracy gains for some applications.
I'll also say that due to the hallucination problem, beyond whatever knowledge is required for being more or less coherent and "knowing" what to write in web search queries, I'm not sure I find more "knowledgeable" LLMs very valuable. Even with proprietary SOTA models hosted on someone else's cloud hardware, I basically never want an LLM to answer "off the dome"; IME it's almost always wrong! (Maybe this is less true for others whose work focuses on the absolute most popular libraries and languages, idk.) And if an LLM I use is always going to be consulting documentation at runtime, maybe that knowledge difference isn't quite so vital— summarization is one of those things that seems much, much easier for language models than writing code or "reasoning".
All of that is to say:
Sure, bigger is better! But for some tasks, my needs are still below the ceiling of the capabilities of a smaller model, and that's where I'm focusing on local usage. For now that's mostly language-focused tasks entirely apart from coding (translation, transcription, TTS, maybe summarization). It may also include simple coding tasks today (e.g., fancy auto-complete, "ghost-text" style). I think it's reasonable to hope that it will eventually include more substantial programming tasks— even if larger models are still preferable for more sophisticated tasks (like "vibe coding", maybe).
If I end up having a lot of fun, in a year or two I'll probably try to put together a machine that can indeed run larger models. :)
> Even with proprietary SOTA models hosted on someone else's cloud hardware, I basically never want an LLM to answer "off the dome"; IME it's almost always wrong! (Maybe this is less true for others whose work focuses on the absolute most popular libraries and languages, idk.)
I feel like I'm the exact opposite here (despite heavily mistrusting these models in general): if I came to the model to ask it a question, and it decides to do a Google search, it pisses me off as I not only could do that, I did do that, and if that had worked out I wouldn't be bothering to ask the model.
FWIW, I do imagine we are doing very different things, though: most of the time, when I'm working with a model, I'm trying to do something so complex that I also asked my human friends and they didn't know the answer either, and my attempts to search for the answer are failing as I don't even know the terminology.
> I feel like I'm the exact opposite here (despite heavily mistrusting these models in general): if I came to the model to ask it a question, and it decides to do a Google search, it pisses me off as I not only could do that, I did do that, and if that had worked out I wouldn't be bothering to ask the model.
When a model does a single web search and emulates a compressed version of the "I'm Feeling Lucky" button, I am disappointed, too. ;)
I usually want the model to perform multiple web searches, do some summarization, refine/adjust search terms, etc. I tend to avoid asking LLMs things that I know I'll find the answer to directly in some upstream official documentation, or a local man page. I've long been and remain a big "RTFM" person; imo it's still both more efficient and more accurate when you know what you're looking for.
But if I'm asking an LLM to write code for me, I usually still enable web search on my query to the LLM, because I don't trust it to "remember" APIs. (I also usually rewrite most or all of the code because I'm particular about style.)
>you might sometimes prefer a smaller one because being able to do something in real-time, or being able to run on a mobile device, is more important than marginal accuracy gains for some applications.
This reminds me of ~”the best camera is the one you have with you” idea.
Though, large models are an http request away, there are plenty of reasons to want to run one locally. Not the least of which is getting useful results in the absence of internet.
All of these models are suitable for translation and that is what they are most suitable for. The architecture inherits from seq2seq and original transformers was created to benefit Google translations.
For coding though it seems like people are willing to pay a lot more for a slightly better model.
The problem with local vs remote isn't so much about paid. It is about compliance and privacy.
For me, the sense of a greater degree of independence and freedom is also important. Especially when the tech world is out of its mind with AI hype, it's difficult to feel the normal tinkerer's joy when I'm playing with some big, proprietary model. The more I can tweak at inference time, the more control I have over the tools in use, the more I can learn about how a model works, and the closer to true open-source the model is, the more I can recover my child-like joy at playing with fun and interesting tech-- even if that tech is also fundamentally flawed or limited, over-hyped, etc.
> HN is weird because at one point this was the location where I found the most technically folks, and now for LLM I find them at reddit.
Is this an effort to chastise the viewpoint advanced? Because his viewpoint makes sense to me: I can run biggish models on my 128GB Macbook but not huge ones-- even 2b quantized ones suck too many resources.
So I run a combination of local stuff and remote stuff depending upon various factors (cost, sensitivity of information, convenience/whether I'm at home, amount of battery left, etc ;)
Yes, bigger models are better, but often smaller is good enough.
The large models are using tools/functions to make them useful. Sooner or later open source will provide a good set of tools/functions for coding as well.
I'd be interested in smaller models that were less general, with a training corpus more concentrated. A bash scripting model, or a clojure model, or a zig model, etc.
Well yes tons of people are running them but they're all pretty well off.
I don't have 10-20k$ to spend on this stuff. Which is about the minimum to run a 480B model, with huge quantisation. And pretty slow because for that price all you get is an old Xeon with a lot of memory or some old nvidia datacenter cards. If you want a good setup it will cost a lot more.
So small models it is. Sure, the bigger models are better but because the improvements come so fast it means I'm only 6 months to a year behind the big ones at any time. Is that worth 20k? For me no.
The small model only needs to get as good as the big model is today, not as the big model is in the future.
There's a niche for small-and-cheap, especially if they're fast.
I was surprised in the AlphaEvolve paper how much they relied on the flash model because they were optimizing for speed of generating ideas.
Not really true. Gemma from Google with quantized aware training does an amazing job.
Under the hood, the way it works, is that when you have final probabilities, it really doesn't matter if the most likely token is selected with 59% or 75% - in either case it gets selected. If the 59% case gets there with smaller amount of compute, and that holds across the board for the training set, the model will have similar performance.
In theory, it should be possible to narrow down models even smaller to match the performance of big models, because I really doubt that you do need transformers for every single forward pass. There are probably plenty of shortcuts you can take in terms of compute for sets of tokens in the context. For example, coding structure is much more deterministic than natural text, so you probably don't need as much compute to generate accurate code.
You do need a big model first to train a small model though.
As for running huge models locally, its not enough to run them, you need good throughput as well. If you spend $2k on a graphics card, that is way more expensive than realistic usage with a paid API, and slower output as well.
> small models can never match bigger models, the bigger models just know more and are smarter
Untrue. The big important issue for LLMs is hallucination, and making your model bigger does little to solve it.
Increasing model size is a technological dead end. The future advanced LLM is not that.
> and now for LLM I find them at reddit. tons of folks are running huge models
Very interesting. Any subs or threads you could recommend/link to?
Thanks
join us at r/LocalLlama
Basically just run ollama and run the quantized models. Don't expect high generation speeds though.
which sub-reddits do you recommend?
The "qwen-code" app seems to be a gemini-cli fork.
https://github.com/QwenLM/qwen-code https://github.com/QwenLM/qwen-code/blob/main/LICENSE
I hope these OSS CC clones converge at some point.
Actually it is mentioned in the page:
we’re also open-sourcing a command-line tool for agentic coding: Qwen Code. Forked from Gemini CodeAlso, kudos to Gemini CLI team for making it open source (unlike claude) and that too easily tunable to new models like Qwen.
It would be great if it starts supporting other models too natively. Wouldn't require people to fork.
What seems to be typical these days is that big companies ship the first tool very fast, in poor condition (applies to Gemini CLI as well), and then let the OSS ecosystem fix the issues. Backend is closed so the app is their best shot. Then after some time the company gets the most credit and not all the contributors.
I tried to use Jetbrains official Kotlin MCP SDK recently and it couldn't even serve the MCP endpoint on an URL that was different than what the default was expected to be...
They had made a bunch of hard-coded assumptions
> They had made a bunch of hard-coded assumptions
Or they simply did that because it is much faster. Adding configuration options requires more testing and input handling. Later on, they can then accept PR where someone needs it a lot, saving their own time.
> then let the OSS ecosystem fix the issues
That's precisely half of the point of OSS and I am pretty much okay with that.
I currently use claude-code as the director basically, but outsource heavy thinking to openai and gemini pro via zen mcp. I could instead use gemini-cli as it's also supported by zen. I would imagine it's trivial to add qwen-coder support if it's based on gemini-cli.
How was your experience using Gemini via Zen?
I’ve instead used a Gemini via plain ol’ chat, first building a competitive, larger context than Claude can hold then manually bringing detailed plans and patches to Gemini for feedback with excellent results.
I presumed mcp wouldn’t give me the focused results I get from completely controlling Gemini.
And that making CC interface via the MCP would also use up context on that side.
I just use it for architecture planning mostly when I want more info and to feed more info to claude. Tougher problems where 3 brains are better.
what is the benefit of outsourcing to other models. do you see any noticable differences?
There are big gains to be had by having one top tier model review the work of another.
For example, you can drive one model to a very good point through several turns, and then have the second “red team” the result of the first.
Then return that to the first model with all of its built up context.
This is particularly useful in big plans doing work on complex systems.
Even with a detailed plan, it is not unusual for Claude code to get “stuck” which can look like trying the same thing repeatedly.
You can just stop that, ask CC to summarize the current problem and attempted solutions into a “detailed technical briefing.”
Have CC then list all related files to the problem including tests, then provide the briefing and all of the files to the second LLM.
This is particularly good for large contexts that might take multiple turns to get into Gemini.
You can have the consulted model wait to provide any feedback until you’ve said your done adding context.
And then boom, you get a detailed solution without even having to directly focus on whatever minor step CC is stuck on. You stay high level.
In general, CC is immediately cured and will finish its task. This is a great time to flip it into planning mode and get plan alignment.
Get Claude to output an update on its detailed plan including what has already been accomplished then again—-ship it to the consulting model.
If you did a detailed system specification in advance, (which CC hopefully was originally also working from) You can then ask the consulting model to review the work done and planned next steps.
Inevitably the consulting model will have suggestions to improve CC’s work so far and plans. Send it on back and you’re getting outstanding results.
We shipped RA.Aid, an agentic evolution of what aider started, back in late '24, well before CC shipped.
Our main focuses were to be 1) CLI-first and 2) truly an open source community. We have 5 independent maintainers with full commit access --they aren't from the same org or entity (disclaimer: one has joined me at my startup Gobii where we're working on web browsing agents.)
I'd love someone to do a comparison with CC, but IME we hold our own against Cursor, Windsurf, and other agentic coding solutions.
But yes, there really needs to be a canonical FOSS solution that is not tied to any specific large company or model.
> I hope these OSS CC clones converge at some point.
Imo, the point of custom CLIs is that each model is trained to handle tool calls differently. In my experience, the tool call performance is wildly different (although they have started converging recently). Convergence is meaningful only when the models and their performance are commoditized and we haven't reached that stage yet.
They also support Claude Code. But my understanding is Claude Code is closed source and only support Clade API endpoint. How do they make it work?
But my understanding is Claude Code is closed source and only support Clade API endpoint. How do they make it work?
You set the environment variable ANTHROPIC_BASE_URL to an OpenAI-compatible endpoint and ANTHROPIC_AUTH_TOKEN to the API token for the service.
I used Kimi-K2 on Moonshot [1] with Claude Code with no issues.
There's also Claude Code Router and similar apps for routing CC to a bunch of different models [2].
That makes sense. Thanks Do you know if this works with AWS Berdrock as well? Or do I need to sort out to use the proxy approach?
Bedrock is officially support by Claude code.
How good is it in comparison? This is an interesting apples to apples situation:)
Claude uses OpenAI-compatible APIs, and Claude Code respects environment variables that change the base url/token.
no it doesn't, claude uses anthropic API. you need to run an anthropic2openAPI proxy
thank you, I stand corrected
Update: Here is what o3 thinks about this topic: https://chatgpt.com/share/688030a9-8700-800b-8104-cca4cb1d0f...
You can use any model from openrouter with CC via https://github.com/musistudio/claude-code-router
I’ll throw out a mention for my project Plandex[1], which predates Claude Code and combines models from multiple providers (Anthropic, Google, and OpenAI by default). It can also use open source and local models.
It focuses especially on large context and longer tasks with many steps.
Have you measured and compared your agent's efficiency and success rate against anything? I am curious. It would help people decide; there are many coding agents now.
Working on it. I’m making a push currently on long horizon tasks, where Plandex already does well vs. alternatives, and plan to include side-by-side comparisons with the release.
Does Plandex have an equivalent to sub-agents/swarm or whatever you want to call it?
I’ve found getting CC to farm out to subagents to be the only way to keep context under control, but would love to bring in a different model as another subagent to review the work of the others.
It has built-in branches, which allow you to share context across as many related tasks as you want: https://docs.plandex.ai/core-concepts/branches
Yes. Just one open-source CC, with a configurable base_url/apikey, that would be great.
Can you run qwen-code locally?
At my work, here is a typical breakdown of time spent by work areas for a software engineer. Which of these areas can be sped up by using agentic coding?
05%: Making code changes
10%: Running build pipelines
20%: Learning about changed process and people via zoom calls, teams chat and emails
15%: Raising incident tickets for issues outside of my control
20%: Submitting forms, attending reviews and chasing approvals
20%: Reaching out to people for dependencies, following up
10%: Finding and reading up some obscure and conflicting internal wiki page, which is likely to be outdated
5% is pretty low but similar to what i have seen on low performing teams at 10K+ employee multinationals. this would also be why the vast majority of software today is bug ridden garbage that runs slower than the software we were using 20 years ago.
agentic coding will not fix these systemic issues caused by organizational dysfunction. agentic coding will allow the software created by these companies to be rewritten from scratch for 1/100th the cost with better reliability and performance though.
the resistance to AI adoption inside corporations that operate like this is intense and will probably intensify.
it takes a combination of external competitive pressure, investor pressure, attrition, PE takeovers, etc, to grind down internal resistance, which takes years or decades depending on the situation.
> 1/100th the cost with better reliability and performance
Cheaper yes. More reliable? Absolutely not. Not with today’s models at least.
Really though? That’s only 2 hours per week writing code.
It’s true to say that time writing code is usually a minority of a developer’s work time, and so an AI that makes coding 20% faster may only translate to a modest dev productivity boost. But 5% time spent coding is a sign of serious organizational disfunction.
This is what software engineers need to be more productive:
- Agentic DevOps: provisions infra and solves platform issues as soon as a support ticket is created.
- Agentic Technical Writer: one GenAI agent writes the docs and keeps the wiki up to date, while another 100 agents review it all and flag hallucinations.
- Agentic Manager: attends meetings, parses emails and logs 24x7 and creates daily reports, shares these reports with other teams, and manages the calendar of the developers to shield them from distractions.
- Agentic Director: spots patterns in the data and approves things faster, without the fear of getting fired.
- Agentic CEO: helps with decision-making, gives motivational speeches, and aligns vision with strategy.
- Agentic Pet: a virtual mascot you have to feed four times a day, Monday to Friday, from your office's IP address. Miss a meal and it dies, and HR gets notified. (This was my boss's idea)
In case of holiday/sick leave do i need to find someone to feed the agentic pet from my ip address? Or is my manager responsability?
Im pretty passive here, but i did log in to upvote this :)
You're not wrong, but it's a "dysfunction" that many successful tech companies have learned to leverage.sign of serious organizational disfunction.The reality is, most engineers spend far less than half their time writing new code. This is where the 80/20 principle comes into play. It's common for 80% of a company's revenue to come from 20% of its features. That core, revenue-generating code is often mature and requires more maintenance than new code. Its stability allows the company to afford what you call "dysfunction": having a large portion of engineers work on speculative features and "big bets" that might never see the light of day.
So, while it looks like a bug from a pure "coding hours" perspective, for many businesses, it's a strategic feature!
I suspect a lot of that organizational dysfunction is related to a couple of things that might be changed by adjusting individual developer coding productivity:
1) aligning the work of multiple developers
2) ensuring that developer attention is focused only on the right problems
3) updating stakeholders on progress of code buildout
4) preventing too much code being produced because of the maintenance burden
If agentic tooling reduces the cost of code ownership, annd allows individual developers to make more changes across a broader scope of a codebase more quickly, all of this organizational overhead also needs to be revisited.
IMHO, the biggest impact LLMs have had in my day to day has not been agentic coding. For example, meeting summarisers are great, it means I sometimes can skip a call or join while doing other things and I still get a list of bullet points afterwards.
I can point at a huge doc for some API and get the important things right away, or ask questions of it. I can get it to review PRs so I can quickly get the gist of the changes before digging into the code myself.
For coding, I don't find agents boost my productivity that much where I was already productive. However, they definitely allow me to do things I was unable to before (or would have taken very long as I wasn't an expert) – for example my type signatures have improved massively, in places where normally I would have been lazy and typed as any I now ask claude to come up with some proper types.
I've had it write code for things that I'm not great at, like geometry, or dataviz. But these are not necessarily increasing my productivity, they reduce my reliance on libraries and such, but they might actually make me less productive.
Why would it be? I'd say it's the opposite. I someone keeps fiddling with the code majority of the time, it means they don't know what they are doing.
New requirements, new features, old bugs being fixed, refactoring code to improve maintainability, writing tests for edge cases previously not discovered, adapting code for different kinds of deployment, ...
Many reasons to touch existing code.
Depending on the workplace, refactoring or bug fixing is not something you just do. You have to create a ticket, meet with other members, discuss approach, scope, prioritise and only play when it is ready to pick up. The touching of the code is small fraction of that time.
Still, to write few hundred lines, doesn't take a whole week.
A few hundred lines of CRUD, maybe not, a few hundred lines of algorithmic code or hard business logic (rare)? That can take more than a week.
I've been on embedded projects where several weeks of work were spent on changing one line of code. It's not necessarily organizational dysfunction. Sometimes it's getting the right data and the right deep understanding of a system, hardware/software interaction, etc, before you can make an informed change that affects thousands of people.
Unfortunately it is true with any org that is rapidly reducing their risk appetite. It is not dysfunctional. It is about balancing the priorities at org level. Risk is distributed very thinly across many people. Heard of re-insurance business? sort of similar thing happens in software development as well.
It means though, that the business positions itself no longer as a software making business. No longer does it value being able to make software things that support its processes, whether those are customer processes or internal processes.
Serious organizational disfunction is a good way to describe most large tech companies.
It doesn't if you have to manually check all that code. (Or even worse, you dump the code into a pull request and force someone else to manually check it - please do not do that.)
"10% running build pipelines + 20% submitting forms" vs 5% making code changes?
Are you in heavily regulated industry or dysfunctional organization?
Most big tech optimize their build pipelines a lot to reduce commit to deploy (or validation/test process) which keeps engineers focus on the same task while problem/solution is fresh.
How about you find out for yourself? Keep a chat window or an agent open and ask it how it could help with your tasks. My git messages and gitlab tickets are being written by AI for a year now, way better than anything I would half heartedly do on my side, really good commit messages too. Claude even reminds me to create/update the ticket.
I find the commits written by AI often inadequate, as they mostly just describe what is already in the diff, but miss the background on why was the change needed, why this approach was chosen, etc, the important stuff...
Then ask it to write the commit differently, or you can explain why in the prompt. Edit: I start by creating the ticket with Claude+terminal tool, the title and descriptions gives context info to the llm, then we do the task, then commit and update the ticket
And in the time it takes to do all of that, the guy could have already written a meaningful commit message and be done with that issue for the day.
And in the time it takes to do all of that, the guy could have already written a meaningful commit message and be done with that issue for the day.
You only have to describe how you want commits written once and then the AI will just handle it. Is not that anyone of us can't write good commits, but humans get tired, lose focus, get interrupted, etc.
Just in my short time using Claude Code, it generally writes pretty good commits; it often adds more detail than I normally would not because I'm not capable but because there's a certain amount of cognitive overhead when it comes to writing good commits and it gets harder as our mental energy decreases.
I found this custom command [1] for Claude Code and it reminded me that there's no way a human can consistently do this every single time, perhaps a dozen times per day, unless they're doing nothing else--no meetings, no phone calls, etc. And we know that's not possible:
[1]: https://github.com/qdhenry/Claude-Command-Suite/blob/main/.c...
# Git Status Command Show detailed git repository status *Command originally created by IndyDevDan (YouTube: https://www.youtube.com/@indydevdan) / DislerH (GitHub: https://github.com/disler)* ## Instructions Analyze the current state of the git repository by performing the following steps: 1. *Run Git Status Commands* - Execute `git status` to see current working tree state - Run `git diff HEAD origin/main` to check differences with remote - Execute `git branch --show-current` to display current branch - Check for uncommitted changes and untracked files 2. *Analyze Repository State* - Identify staged vs unstaged changes - List any untracked files - Check if branch is ahead/behind remote - Review any merge conflicts if present 3. *Read Key Files* - Review README.md for project context - Check for any recent changes in important files - Understand project structure if needed 4. *Provide Summary* - Current branch and its relationship to main/master - Number of commits ahead/behind - List of modified files with change types - Any action items (commits needed, pulls required, etc.) This command helps developers quickly understand: - What changes are pending - The repository's sync status - Whether any actions are needed before continuing work Arguments: $ARGUMENTSIt's not possible for a human to do what an LLM does at scale, for sure. But that's the difference, humans are not robots, so they will turn the the problem around and will try to find ways on how to not have to do this in the first place. E.g. minimizing pending changes left around by making small frequent commits. A lot of invention comes from people being annoyed doing something all over again manually. LLM stirs up things a little bit as it provides a completely different way of doing such tasks. You don't have to invent a better process if the LLM can do it repeatedly for a reasonable price. The new pressure then comes from minimizing LLM costs, I guess.
Wishful thinking. They will often ignore your general instructions, due to the statistical nature of their output. Source: have many such detailed general instructions that routinely get ignored.
Have you tried?
No, you see - I have my own brains and don't need to invest more effort in describing a trivial task, than actually doing it myself.
So no, maybe give it a try before talking about it? You know, having an informed opinion and all…
These tools aren't magic, if there are reasons for code changes outside of the diff LLMs aren't going to magically fabricate a commit message that gives that context.
If you were having a Claude code session, it will know the context from the discussion.
Do you feed the LLM additional context for the commit message, or it is just summarising what’s in the commit? In the latter case, what’s the point? The reader can just get _their_ LLM to do a better job.
In the former case… I’m interested to hear how they’re better? Do you choose an agent with the full context of the changes to write the message, so it knows where you started, why certain things didn’t work? Or are you prompting a fresh context with your summary and asking it to make it into a commit message? Or something else?
Depends, I have a prompt ready for changes I made manually, that checks the diff, gets the context, spits a conventional commit with a summary of the changes, I check, correct if needed and add the ticket number. It’s faster because it types really fast, no time thinking about phrasing and remembering the changes, and usually way more complete then what I would have written, given time constraints.
If I’m using a CLI:
the agent already has: - the context from the chat - the ticket number via me or when it created the ticket - meta info via project memory or other terminal commands like API call etc - Info on commit format from project memory
So it boils down to asking it to commit and update the ticket when we’re done with the task in that case. Having a good workflow is key
For your question: I still read and validated/correct, in the end I’m the one committing the code! So it’s the usual requirements from there. If someone would use their LLM the results would vary, here they have an approved summary. This is why human in the loop is essential.
Interesting approach. I'm a bit old-school, when I make a change I already have all the context and beyond in my head, plus all the expectations from colleagues, historical context etc that might be useful to remind people about. At least for me, it is easier to formulate the commit based on that, than trying to formulate a prompt to formulate what I want to have in the commit. But I have the same with code. When it is born in my head, it's usually easier for me to write what I want, than trying to explain it to an LLM. I find the LLM a bit lacking precision when it comes to comprehension, a little like trying to explain something to a child (with superpowers, but still need step by step directions).
But I find it very interesting how others find prompting more productive for their use cases. It's definitely a new skill. Over years I also built my skill to write commits, so it comes natural to me as opposed to prompting, which requires extra effort and thinking in a different way and context and it doesn't work well for something that I do basically automatically already.
I’m from the old guard, I get where you’re coming from. The thing is when I find a prompt that works well, I can reuse it, build on it, create new rules, all in natural language.
Give it a try it’s kind of impressive
It’s definitely a new skill.
[flagged]
You are saying that people need to write so complex that an LLM that can pass an LSAT test with flying colors is unable to summarize its changes in a few sentences, or else their work is not critical? That is a high bar.
I am not sure what tests LLMs are passing these days. Every day its some other metric of no practical usage. You know we make money by delivering working code and features. What I do know is that for myself and people working for me at my company, we hit the limits of their practical usage so often,not even counting the casual removal of entire parts of code, that we recently decided to revert back from agents to using them again only in the conversational mode and only for select tasks. Whoever claims these tools are revolutionary is clearly not using them intensively enough or does not have a challenging use case. We get it, they can quickly spit out a react app for you, the frontend devs and people who were never good at maths are finally "good" at something vaguely technical. However -try using them for production-ready products over several months every day, your opinion will likely change.
>We get it, they can quickly spit out a react app for you, the frontend devs and people who were never good at maths are finally "good" at something vaguely technical
The LLM is better than you at math, too.
https://www.reuters.com/world/asia-pacific/google-clinches-m...
Plenty of us are using LLM/agentic coding in highly regulated production applications. If you're not getting very impressive results in backend and frontend, it's purely a skill issue on your part. "This hammer sucks because I hit my thumb every time!"
Again mate, not relevant. Oh how about this. Show me one major application that was developed mainly with LLMs and that was a huge success by any measure (does not have to be profitability). Again the benchmarks show what benchmarks show, but we have yet to see some killer app done by the LLMs (or mostly LLMs).
You started with insulting someone for using an LLM to write git commit messages, and in order to defend that statement you say that an LLM hasn't written a killer app by itself.
I am not really sure what to say except that if you are simply looking for a way to insult people, just admit you are a mean person and you won't have to justify in ways that make no sense. But if you really only hate LLMs, you can do that in ways that don't involve insulting people. But to be so full of disdain for a technology that it turns you irrational is something that should be a bit concerning.
Insulting, really? I merely made a statement about the nature of their work. That's not an insult. Please re-read and understand, before conflating. Also you fully misunderstood my comments about the LLMs. If I had disdain I would not have dished out thousands of USD for my team to use them. I am merely saying that they are not what the hype-makers would have you believe. Now show me that one killer app that someone successfully vibe-coded? All we see is theoretical bullshit, benchmarks etc. But no real-world a-ha moment.
You just felt like coming into a thread which was bound to be populated by people talking about using LLM for coding to let them know that their work isn't important because they use an LLM.
It seems to me the only reason someone would feel the need to do such a thing is to validate their own experience. If everyone else seems to be finding value in a tool, but you cannot, it must be because everyone else just isn't doing important things with it.
As I said earlier, I would be concerned about such behavior if I found myself doing it.
[flagged]
I own my own company, so I kind of already have "jobs" that I do not need to compete for.
We must have the same job! Generating code is a miniscule part of my job. We have the same level of organizational disfunction. Mostly the work part involves long investigations of customer bugs and long face to face calls with customers - I'm only getting the stuff that stumped level 1 and level 2 support.
I actually tried to use Qwen3[1] to analyse customer cases and it was worse than useless at it.
[1] We can't use any online model as these bug reports contain large amounts of PII, customer data, etc.
In theory, nearly all of them?
Many of those things could be improved today without AI but e.g. raising Incidents for issues outside of your control could also give you a suggestion already that you just have to tick off.
Not saying we are there yet but hard to imagine it's not possible.
Raising incidents is not about suggestions. Things like build pipelines run into issues, someone from Ops need to investigate, and maybe bump up some pods or apply some config changes on their end. Or some wiki page has conflicting information, someone need to update it with correct information after checking with the relevant other people, policies and standards. The other people might be on vacation and their delegate misguides as they are not aware of the recently changed process.
It's probably messier than you think.
Your place is work sucks
Also, you're not making an argument against agentic coding, you're actually making an argument for it - you don't have time to code, so you need someone or something to code for you.
You should automate this, like i did. You're an engineer, no? Work around the digital bureaucracy.
- Running build pipelines: make cli tool to initiate them, monitor them and notify you on completion/error (audio). Allows to chain multiple things. Run in background terminal.
- Learning about changed process and people via zoom calls, teams chat and emails: pass logs of chats and emails to LLM with particular focus. Demand zoom calls transcripts published for that purposes (we use meet)
- Raising incident tickets for issues outside of my control: automate this with agent: allow it to access as much as needed, and guide it with short guidance - all doable via claude code + custom MCP
- Submitting forms, attending reviews and chasing approvals - best thing to automate. They want forms? They will have forms. Chasing approvals - fire and forget + queue management, same.
- Reaching out to people for dependencies, following up: LLM as personal assistant is classic job. Code this away.
- Finding and reading up some obscure and conflicting internal wiki page, which is likely to be outdated: index all data and put it into RAG, let agent dig deeper.
Most of the time you spend is on scheduling micro-tasks, switching between them and maintaining unspoken queue of checking various saas frontends. Formalize micro-task management, automate endpoints, and delegate it to your own selfware (ad-hoc tools chain you vibe coded for yourself only, tailored for particular working environment).
I do this all (almost) to automate away non-coding tasks. Life is fun again.
Hope this helps.
Please name the company you work for so everyone can avoid it. That's insane, unless you're a lead engineer whose job is primarily to oversee things
You can cut all of them in half by using agentic coding because afterwards 50% of your timer will be spend fixing prod issues from the "agentic code"
In the short term, I think humans will be doing more of technical / product alignment, f2f calls (especially with non-technical folks), digesting illegible requirements, etc.
Coding, debugging builds, paperwork, doc chasing are all tasks that AI is improving on rapidly.
If 95% of employee time is work coordination, then executive leadership needs to downsize aggressively. This is a comical example of Brooks Law. Likewise, your clients or customers should be outraged and demand proof that pricing reflects business value and $0.95 of every dollar they give your company isn’t wasted.
There are so many problems in the world we need to stop cramming into the same bus.
Very similar to my job, although its very variable: some weeks I do write / debug code 80-90% of the time.
1x dev - only adds up to 100%
I've been using it all day, it rips. Had to bump up toolcalling limit in cline to 100 and it just went through the app no issues, got the mobile app built, fixed throug hthe linter errors... wasn't even hosting it with the toolcall template on with the vllm nightly, just stock vllm it understood the toolcall instructions just fine
Im interested in more info? Where do you host it? Whats the hardware, and exact model? What t/s do you get? What is the codebase size? Etc pls, thank you
Nice, what model & on what hardware?
Welp, time to switch aider models for the _second_ time in a week...
How good is it at editing files? Many write/replace errors?
so are you tell where you hosted it?
This suggests adding a `QWEN.md` in the repo for agents instructions. Where are we with `AGENTS.md`? In a team repo it's getting ridiculous to have a duplicate markdown file for every agent out there.
I just symlink to AGENTS.md, the instructions are all the same (and gitignore the model-specific version).
I just make a file ".llmrules" and symlink these files to it. It clutters the repo root, yes...
Can't these hyper-advanced-super-duper tools discover what UNIX tools since circa 1970 knew, and just have a flag/configuration setting pointing them to the config file location? Excuse me if they already do :-)
In which case you'd have 1 markdown file and at least for the ones that are invoked via the CLI, just set up a Makefile entry point that leads them to the correct location.
CLAUDE.md MISTRAL.md GEMINI.md QWEN.md GROK.md .cursorrules .windsurfrules .copilot-instructions
Saw a repo recently with probably 80% of those
It would be funny to write conflicting instructions on these, and then unleash different coding agents on the same repo in parallel, and see which one of them first identifies the interference from the others and rewrites their instructions to align with its own.
Core War NG!
Lol you can even tell each model to maliciously and secretly sabotage other agents and see which one wins.
I built https://github.com/czottmann/render-claude-context for that exact reason.
> This node.js CLI tool processes CLAUDE.md files with hierarchical collection and recursive @-import resolution. Walks directory tree from current to ~/.claude/, collecting all CLAUDE.md files and processing them with file import resolution. Saves processed context files with resolved imports next to the original CLAUDE.md files or in a specific location (configurable).
I mostly use Claude Code, but every now and then go with Gemini, and having to maintain two sets of (hierarchical) instructions was annoying. And then opencode showed up, which meant yet another tool I wanted to try out and …well.
Maybe there could be an agent that is in charge of this and it's trained to automatically create a file for any new agent, it could even temporarily delete local copies of MD files that no agents are using at the moment to free the visual clutter when navigating the repo.
I tried making an MCP with the common shit I need to tell the agents, but it didn't pan out.
Now I have a git repo I add as a submodule and tell each tool to read through and create their own WHATEVER.md
https://github.com/intellectronica/ruler
Library to help with this. Not great that a library is necessary, but useful until this converges to a standard (if it ever does).
these files are for free publicity on github
I tried using the "fp8" model through hyperbolic but I question if it was even that model. It was basically useless through hyperbolic.
I downloaded the 4bit quant to my mac studio 512GB. 7-8 minutes until first tokens with a big Cline prompt for it to chew on. Performance is exceptional. It nailed all the tool calls, loaded my memory bank, and reasoned about a golang code base well enough to write a blog post on the topic: https://convergence.ninja/post/blogs/000016-ForeverFantasyFr...
Writing blog posts is one of the tests I use for these models. It is a very involved process including a Q&A phase, drafting phase, approval, and deployment. The filenames follow a certain pattern. The file has to be uploaded to s3 in a certain location to trigger the deployment. It's a complex custom task that I automated.
Even the 4bit model was capable of this, but was incapable of actually working on my code, prefering to halucinate methods that would be convenient rather than admitting it didn't know what it was doing. This is the 4 bit "lobotomized" model though. I'm excited to see how it performs at full power.
How does one keep up with all this change? I wish we could fast-forward like 2-3 years to see if an actual winner has landed by then. I feel like at that point there will be THE tool, with no one thinking twice about using anything else.
One keeps up with it, by keeping up with it. Folks keep up with latest social media gossip, the news, TV shows, or whatever interests them. You just stay on it. Weekend I got to running Kimi K2, last 2 days I have been driving Ernie4.5-300B, Just finished downloading the latest Qwen3-235b this morning and started using it this evening. Tonight I'll start downloading this 480B, might take 2-3 days with my crappy internet and then I'll get to it.
Obsession?
Do you write about your assessments of model capabilities and the results of your experiments?
what kind of hardware do you run it on?
I would simply call it a healthy level of curiosity :-)
No, it's unhealthy. Folks already have day jobs, families, other responsibilities.
Having to tack on top of that 2-4h of work per day is not normal, and again, it's probably unhealthy.
Not if you see it as a hobby.
Ergo my point about work and personal obligations (family, especially small kids). 2-4 hours per day for a solitary hobby is a surefire way to a divorce and estranged kids.
I'm married, kids, got an elderly parent at end of life that I'm caring for, and so on and so forth. How do I do it? Balance, right now, the kids are packing their bags to go to camp, so I have about 10 mins. I just replied to my prompt from last night, and will head out to drop them off, when I come in, I'll have a reply and enter my next prompt before I sign in for work. When the kids come in from school, they stay in my office and do their workbooks or watch TV while I sink in some work. You don't have to stay there for 4 straight hours, I get on the computer for 5 minutes, do a few and step out, then from that time till I get back on, I keep thinking about whatever problem I'm trying to solve.
not everyone has those personal obligations.
Just ignore it until something looks useful. There's no reason to keep up, it's not like it takes 3 years experience to type in a prompt box.
> it's not like it takes 3 years experience to type in a prompt box
This should be written on the coffin of full stack development.
Yeah second this. I find model updates mildly interesting, but besides grok 4 I haven’t even tried a new model all year.
Its a bit like the media cycle. The more jacked in you are, the more behind you feel. I’m less certain there will be winners as much as losers, but for sure the time investment on staying up to date on these things will not pay dividends to the average hn reader
It depends on the level of 'keeping up'. I follow the news, but it's impossible to dip your toe in every new model. Some stick around, but the majority pass through.
I'm using claude code and making stuff. I'm keeping an eye and being aware of these new tools but I wait for the dust to settle and see if people switch or are still hyped after the hype dies down. X / HackerNews are good for keeping plugged in.
don't bother at all
assuming it doesn't all implode due to a lack of profitability, it should be obvious
The underlying models are apparently profitable. Inference costs are in a exponential fall that makes Gordon Moore faint. OpenRouter shows Anthropic, AWS, Google host Claude at same rates, apparently nobody is price dumping.
That said, code+git+agent is only acceptable way for technical staff to interact with AI. Tools with sparkles button can go to hell.
https://a16z.com/llmflation-llm-inference-cost/ https://openrouter.ai/anthropic/claude-sonnet-4
if I dropped 99.999999% of my costs I'd be Google level profitable too
I was thinking this exact same thing last night.
We don't actually need a winner, we need 2-3-4 big, mature commercial contenders for the state of the art stuff, and 2-3-4 big, mature Open Source/open weights models that can be run on decent consumer hardware at near real-time speeds, and we're all set.
Sure, there will probably be a long tail, but the average programmer probably won't care much about those, just like they don't care about Erlang, D, MoonScript, etc.
I think in 2-3 years, it'll be the same story except it'll be bigger/better/faster.
As Heraclitus said "The only constant in life is change"
(and maybe Emacs)
Things will be moving faster in 2-3 years most likely. (The recursive self-improvement flywheel is only just starting to pick up momentum, and we’ll have much more LLM inference compute available.)
Figuring out how to stay sane while staying abreast of developments will be a key skill to cultivate.
I’m pretty skeptical there will be a single model with a defensible moat TBH. Like cloud compute, there is both economy of scale and room for multiple vendors (not least because bigco’s want multiple competing bids).
I'm actually waiting for something different - a "good enough" level for programming LLMs:
1. Where they can be used as autocompletion in an IDE at speeds comparable with Intellisense 2. And where they're good enough to generate most code reliably, while using a local LLM 3. While running on hardware costing in total max 2000€ 4. And definitely with just a few "standard" pre-configured Open Source/open weights LLMs where I don't have to become an LLM engineer to figure out the million knobs
I have no clue how Intellisense works behind the scenes, yet I use it every day. Same story here.
“Good enough” will be like programming languages; an evolving frontier with many choices. New developments will make your previous “good enough” look inadequate.
Given how much better the bleeding edge models are now than 6 months ago, as long as any model is getting smarter I don’t see stagnation as a possibility. If Gemini starts being better at coding than Claude, you’re gonna switch over if your livelihood is dependent on it.
Mass adoption is rarely a quality indicator. I wouldn't want to pay for the mainstream VHS model(s) when I could use Betamax (perhaps even cheaper).
A look at fandom wikis is humbling. People will persist and go very deep into stuff they care about.
In this case: Read a lot, try to build a lot, learn, learn from mistakes, compare.
> Mass adoption is rarely a quality indicator. I wouldn't want to pay for the mainstream VHS model(s) when I could use Betamax (perhaps even cheaper).
Oh, but it is.
Imagine you were then, back in those days. A few years after VHS won, you couldn't find your favorite movies on Betamax. There was a lot more hardware, and cheaper, available, for VHS.
Mass adoption largely wins out over almost everything.
Case in point from software: Visual Basic, PHP, Javascript, Python (though Python is slightly more technically sound than the other ones), early MySQL, MongoDB, early Windows, early Android.
Why do you believe so? The leaderboard is highly unstable right now and there are no signs of that subsiding. I would expect the same situation 2-3 years forward, just possibly with somewhat different players.
It's hard to avoid if you frequent HN
What sort of hardware will run Qwen3-Coder-480B-A35B-Instruct?
With the performance apparently comparable to Sonnet some of the heavy Claude Code users could be interested in running it locally. They have instructions for configuring it for use by Claude Code. Huge bills for usage are regularly shared on X, so maybe it could even be economical (like for a team of 6 or something sharing a local instance).
I'm currently trying to make dynamic GGUF quants for them! It should use 24GB of VRAM + 128GB of RAM for dynamic 2bit or so - they should be up in an hour or so: https://huggingface.co/unsloth/Qwen3-Coder-480B-A35B-Instruc.... On running them locally, I do have docs as well: https://docs.unsloth.ai/basics/qwen3-coder
Any significant benefits at 3 or 4 bit? I have access to twice that much VRAM and system RAM but of course that could potentially be better used for KV cache.
So dynamic quants like what I upload are not actually 4bit! It's a mixture of 4bit to 8bit with important layers being in higher precision! I wrote about our method here: https://docs.unsloth.ai/basics/unsloth-dynamic-2.0-ggufs
For coding you want more precision so the higher the quant the better. But there is discussion if a smaller model in higher quant is better than a larger one in lower quant. Need to test for yourself with your use cases I'm afraid.
e: They did announce smaller variants will be released.
Yes the higher the quant, the better! The other approach is dynamically choosing to upcast some layers!
I can say that this really works great, I'm a heavy user of the unsloth dyanmic quants. I run DeepSeek v3/r1 in Q3, and ernie-300b and KimiK2 in Q3 too. Amazing performance. I run Qwen3-235b in both Q4 and Q8 and can barely tell the difference so much so that I just keep Q4 since it's twice as fast.
What hardware do you use, out of curiosity?
In the current era of MoE models, the system RAM memory bandwidth determines your speed more than the GPU does.
Thanks for using them! :)
You definitely want to use 4bit quants at minimum.
https://arxiv.org/abs/2505.24832
LLMs usually have about 3.6 bits of data per parameter. You're losing a lot of information if quantized to 2 bits. 4 bit quants are the sweet spot where there's not much quality loss.
I would say that three or four bit are likely to be significantly better. But that’s just from my previous experience with quants. Personally, I try not to use anything smaller than a Q4.
Legend
:)
There's a 4bit version here that uses around 272GB of RAM on a 512GB M3 Mac Studio: https://huggingface.co/mlx-community/Qwen3-Coder-480B-A35B-I... - see video: https://x.com/awnihannun/status/1947771502058672219
That machine will set you back around $10,000.
You can get similar performance on an Azure HX vm:
https://learn.microsoft.com/en-us/azure/virtual-machines/siz...
How? These don't even have GPU's right?
They have similar memory bandwidth compared to the Mac Studio. You can run it off CPU at the same speed.
Interesting, so with enough memory bandwidth, even the server CPU has enough compute to do inference on a rather large model? Enough to compete against M4 gpu?
Edit: I just aked chatgpt and it says with no memory bandwidth bottleneck, i can still only achieve around 1 token/s from a 96 core cpu.
For a single user prompting with one or few prompts at a time, compute is not the bottleneck. Memory bandwidth is. This is because the entire model's weights must be run through the algorithm many times per prompt. This is also why multiplexing many prompts at the same time is relatively easy and effective, as many matrix multiplications can happen in the time it takes to do a single fetch from memory.
> This is because the entire model's weights must be run through the algorithm many times per prompt.
And this is why I'm so excited about MoE models! qwen3:30b-a3b runs at the speed of a 3B parameter model. It's completely realistic to run on a plain CPU with 20 GB RAM for the model.
Yes, but with a 400B parameter model, at fp16 it's 800GB right? So with 800GB/s memory bandwidth, you'd still only be able to bring them in once per second.
Edit: actually forgot the MoE part, so that makes sense.
Approximately, yes. For MoE models, there is less required bandwidth, as you're generally only processing the weights from one or two experts at a time. Though which experts can change from token to token, so it's best if all fit in RAM. The sort of machines hyperscalers are using to run these things have essentially 8x APUs each with about that much bandwidth, connected to other similar boxes via infiniband or 800gbps ethernet. Since it's relatively straightforward to split up the matrix math for parallel computation, segmenting the memory in this way allows for near linear increases in memory bandwidth and inference performance. And is effectively the same thing you're doing when adding GPUs.
Out of curiosity I've repeatedly compared the tokens/sec of various open weight models and consistently come up with this: tokens/sec/USD is near constant.
If a $4,000 Mac does something at X tok/s, a $400 AMD PC on pure CPU does it at 0.1*X tok/s.
Assuming good choices for how that money is spent. You can always waste more money. As others have said, it's all about memory bandwidth. AMD's "AI Max+ 395" is gonna make this interesting.
And of course you can always just not have enough RAM to even run the model. This tends to happen with consumer discrete GPUs not having that much VRAM, they were built for gaming.
ChatGPT is wrong.
Here's Deepseek R1 running off of RAM at 8tok/sec: https://www.youtube.com/watch?v=wKZHoGlllu4
Ugh, why is Apple the only one shipping consumer GPUs with tons of RAM?
I would totally buy a device like this for $10k if it were designed to run Linux.
Intel already has a great value GPU. Everyone wants them to disrupt the game, destroy the product niches. It's general purpose compute performance is quite ass alas but maybe that doesn't matter for AI?
I'm not sure if there are higher capacity gddr6 & 7's rams to buy. I semi doubt you can add more without more channels, to some degree, but also, AMD just shipped R9700 based on rx9070 but with double the ram. But something like Strix Halo, an API with more lpddr channels could work. Word is that Strix Halo's 2027 successor Medusa Halo will go to 6 channels and it's hard to see a significant advantage without that win; the processing is already throughput constrained-ish and a leap on memory bandwidth will definitely be required. Dual channel 128b isn't enough!
There's also MRDIMMs standard, which multiplexes multiple chips. That promises a doubling of both capacity and throughout.
Apple's definitely done two brilliant costly things, by putting very wide (but not really fast) memory on package (Intel had dabbled in doing similar with regular width ram in consumer space a while ago with Lakefield). And then by tiling multiple cores together, making it so that if they had four perfect chips next to each other they could ship it as one. Incredibly brilliant maneuver to get fantastic yields, and to scale very big.
You can buy a RTX 6000 Pro Blackwell for $8000-ish which has 96GB VRAM and is much faster than the Apple integrated GPU.
In depth comparison of an RTX vs. M3 Pro with 96 GB VRAM: https://www.youtube.com/watch?v=wzPMdp9Qz6Q
It's not faster at running Qwen3-Coder, because Qwen3-Coder does not fit in 96GB, so can't run at all. My goal here is to run Qwen3-Coder (or similarly large models).
Sure you can build a cluster of RTX 6000s but then you start having to buy high-end motherboards and network cards to achieve the bandwidth necessary for it to go fast. Also it's obscenely expensive.
You can get 128GB @ ~500GB/s now for ~$2k: https://a.co/d/bjoreRm
It has 8 channels of DDR5-8000.
AMD says "256-bit LPDDR5x"
It might be technically correct to call it 8 channels of LPDDR5 but 256-bits would only be 4 channels of DDR5.
DDR5 uses 32bit channels as well. A DDR5 DIMM holds two channels accessed separately.
Per above, you need 272GB to run Qwen3-Coder (at 4 bit quantization).
wrong it is approx half bandwith
That's very informative, thanks! So a DGX H200 should be able to run it at 16-bit precision. If I recall correctly, the current hourly rate should be around $25. Not sure what the throughput is, though.
To run the real version with the bench arks they give, it would be a nonquantized non distilled version. So I am guessing that is a cluster of 8 H200s if you want to be more or less up to date. They have B200s now which are much faster but also much more expensive. $300,000+
You will see people making quantized distilled versions but they never give benchmark results.
Oh you can run the Q8_0 / Q8_K_XL which is nearly equivalent to FP8 (maybe off by 0.01% or less) -> you will need 500GB of VRAM + RAM + Disk space. Via MoE layer offloading, it should function ok
This should work well for MLX Distributed. The low activation MoE is great for multi node inference.
1. What hardware for that. 2. Can you do a benchmark?
With RAM you would need at least 500gb to load it but some 100-200gb more for context too. Pair it with a 24gb GPU and the speed will be 10t/s, at least, I estimate.
Oh yes for the FP8, you will need 500GB ish. 4bit around 250GB - offloading MoE experts / layers to RAM will definitely help - as you mentioned a 24GB card should be enough!
Do we know if the full model is FP8 or FP16/BF16? The hugging face page says BF16: https://huggingface.co/Qwen/Qwen3-Coder-480B-A35B-Instruct
So likely it needs 2x the memory.
I think it's BF16 trained then quantized to FP8, but unsure fully - I was also trying to find out if they used FP8 for training natively!
Qwen uses 16bit, Kimi and Deepseek uses FP8.
Oh ok cool thanks!
A Mac Studio 512GB can run it in 4bit quantization. I'm excited to see unsloth dynamic quants for this today.
The initial set of prices on OpenRouter look pretty similar to Claude Sonnet 4, sadly.
Do need to be super fancy. Just RTX Pro 6000 and 256GB of RAM.
A mac studio can run it at 4bit. Maybe at 6 bit.
xeon 6980P which now costs 6K€ instead of 17K€
Glad to see everyone centering on using OpenHands [1] as the scaffold! Nothing more frustrating than seeing "private scaffold" on a public benchmark report.
more info on AllHands from robert (above) https://youtu.be/o_hhkJtlbSs
How is cognition so incompetent? They got hundreds of millions of dollars but now they're not just supplanted by Cursor and Claude Code but also by their literal clone, an outfit that was originally called "OpenDevin".
The AI space is attracting alot of grifters. Even the initial announcement for devin was reaking of elon musk style overpromising.
Im sure the engineers are doing the best work they can. I just dont think leadership is as interested in making a good product as they are in creating a nice exit down the line
I just finally got devstral working well.
Openhands is clearly the best ive used so far. Even gemini cli is lesser.
Are you purposefully ignoring Zed?
I just checked and it's up on OpenRouter. (not affiliated) https://openrouter.ai/qwen/qwen3-coder
> Additionally, we are actively exploring whether the Coding Agent can achieve self-improvement
How casually we enter the sci-fi era.
I don’t get the feeling that the amount of money being spent is at all casual.
We have self driving cars, humanoid robots, and thinking machines. I think we're there.
Casual and safe daily use of hoverboards and meal-in-a-pill are my indicators. I think we're not quite there yet, but everyone's different!
...and "No roads". Don't forget no roads! :-)
I've been using it within Claude Code via ccr[0] and it feels very similar to Claude 4.
Open weight models matching Cloud 4 is exciting! It's really possible to run this locally since it's MoE
Where do you put the 480 GB to run it at any kind of speed? You have that much RAM?
You can get a used 5 year old Xeon Dell or Lenovo Workstation and 8x64GB of ECC DDR4 RAM for about $1500-$2000.
Or you can rent a newer one for $300/mo on the cloud
Everyone keeps saying this but it is not really useful. Without a dedicated GPU & VRAM, you are waiting overnight for a response... The MoE models are great but they need dedicated GPU & VRAM to work fast.
Well, yeah, you're supposed to put in a GPU. It's a MoE model, the common tensors should be on the GPU, which also does prompt processing.
The RAM is for the 400gb of experts.
It's 480B params, not 480GB. The 4 bit version of this is 270GB. I believe it's trained at bf16, so you need over a TB of memory to operate the model at bf16. No one should be trying to replace claude with a quantized 8 bit or 4 bit model. It's simply not possible. Also, this model isn't going to be as versed as Claude at certain libraries and languages. I have something written entirely my claude which uses the Fyne library extensively in golang for UI. Claude knows it inside and out as it's all vibe coded, but the 4 bit Qwen3 coder just hallucinated functions and parameters that don't exist because it wasn't willing to admit it didn't know what it was doing. Definitely don't judge a model by it's quant is all I'm saying.
You rent an a100x8 or higher and pay $10k a month in costs, which will work well if you have a whole team using it and you have the cash. I’ve seen people spending $200-500 per day on Claude code. So if this model is comparable to Opus then it’s worth it.
If you're running it for personal use, you don't need to put all of it onto GPU vram. Cheap DDR5 ram is fine. You just need a GPU in the system to do compute for the prompt processing and to hold the common tensors that run for every token.
For reference, a RTX 3090 has about 900GB/sec memory bandwidth, and a Mac Studio 512GB has 819GB/sec memory bandwidth.
So you just need a workstation with 8 channel DDR5 memory, and 8 sticks of RAM, and stick a 3090 GPU inside of it. Should be cheaper than $5000, for 512GB of DDR5-6400 that runs at a memory bandwidth of 409GB/sec, plus a RTX 3090.
> So if this model is comparable to Opus then it’s worth it.
Qwen says this is similar in coding performance to Sonnet 4, not Opus.
You don't actually need 480GB of RAM, but if you want at least 3 tokens / s, it's a must.
If you have 500GB of SSD, llama.cpp does disk offloading -> it'll be slow though less than 1 token / s
> but if you want at least 3 tokens / s
3 t/s isn't going to be a lot of fun to use.
beg to differ, I'm living fine with 1.5tk/sec
Spec decoding on a small draft model could help increase it by say 30 to 50%!
i'm not willing to trade any more quality for performance. no draft, no cache for kv either. i'll take the performance cost, it just makes me think carefully about my prompt. i rarely every need more than one prompt to get my answers. :D
Speculative decoding doesn't change output tokens.
Draft model doesn’t degrade quality!
I beg to differ, especially when it comes to code.
As far as inference costs go 480GB of RAM is cheap.
Ye! Super excited for Coder!!
Odd to see this languishing at the bottom of /new. Looks very interesting.
Open, small, if the benchmarks are to be believed sonnet 4~ish, tool use?
Qwen has previously engaged in deceptive benchmark hacking. They previously claimed SOTA coding performance back in January and there's a good reason that no software engineer you know was writing code with Qwen 2.5.
https://winbuzzer.com/2025/01/29/alibabas-new-qwen-2-5-max-m...
Alibaba is not a company whose culture is conducive to earnest acknowledgement that they are behind SOTA.
Maybe not the big general purpose models, but Qwen 2.5 Coder was quite popular. Aside from people using it directly I believe Zed's Zeta was a fine-tune of the base model.
Benchmarks are one thing but the people really using these models, do it for a reason. Qwen team is top in open models, esp. for coding.
> there's a good reason that no software engineer you know was writing code with Qwen 2.5.
this is disingenous. there are a bunch of hurdles to using open models over closed models and you know them as well as the rest of us.
There is also paranoia that the Chinese government may compel their tech companies to play dirty tricks on their users. Yet without a trace of irony the critics have nothing to say about this not-so-secret practice for US based technology companies.
Clearly the thing we should want is a healthy, international AI ecosystem characterized both by cooperation and by competition, so that we are free to choose between models developed under different conditions, for compliance with different laws, subject to different cultures and biases, pressured by different interests, etc.
To the extent that there's a solution, the solution is choice!
Those hurdles exist because they're worse for most people. You think Cursor wouldn't spin up their own Qwen inference cluster or contract with someone who can if doing so would give them SOTA code editing performance against Claude?
Also dishonest since the reason Qwen 2.5 got so popular is not so much paper performance.
Ye the model looks extremely powerful! I think they're also maybe making a small variant as well, but unsure yet!
Yes they are:
"Today, we're announcing Qwen3-Coder, our most agentic code model to date. Qwen3-Coder is available in multiple sizes, but we're excited to introduce its most powerful variant first: Qwen3-Coder-480B-A35B-Instruct."
Oh yes fantastic! Excited for them!
It says that there are multiple sizes in the second sentence of the huggingface page: https://huggingface.co/Qwen/Qwen3-Coder-480B-A35B-Instruct
You won't be out of work creating ggufs anytime soon :)
:)
Anybody knows if one can find an inference provider that offers input token caching? It should be almost required for agentic use - first speed, but also almost all conversations start where the previous ended, so cost may end up quite higher with no caching.
I would have expected good providers like Together, Fireworks, etc support it, but I can't find it, except if I run vllm myself on self-hosted instances.
Alibaba Cloud does: > Supported models. Currently, qwen-max, qwen-plus, qwen-turbo, qwen3-coder-plus support context cache.
I know. I cannot believe lm studio. Ollama. Especially model providers, do not offer this yet.
Much faster than Claude Sonnet 4 with similar results.
Care to share more specifics/ your comparison case?
Looking forward to using this on Cerebras!
Pretty solid at SQL generation, too. Just tested in our generation benchmark: https://llm-benchmark.tinybird.live/
Not quite as good as Claude but by the best Qwen model so far and 2x as fast as qwen3-235b-a22b-07-25
Specific results for qwen3-coder here: https://llm-benchmark.tinybird.live/models/qwen3-coder
does anyone understand pricing ? On OpenRouter (https://openrouter.ai/qwen/qwen3-coder) you have:
Alibaba Plus: input: $1 to $6 output: $5 to $60
Alibaba OpenSource: input: $1.50 to $4.50 output: $7.50 to $22.50
So it doesn't look that cheap comparing to Kimi k2 or their non coder version (Qwen3 235B A22B 2507).
What's more confusing this "up to" pricing that supposed to can reach $60 for output - with agents it's not that easy to control context.
Found out this on simonw blog [0]: "his is the first model I've seen that sets different prices for four different sizes of input" [1]
It seems now a every expensive model to run with alibaba as provider. You only get this low price for input <32k. For input <256k both gemini 2.5 pro and o3 is cheaper.
[0] https://simonwillison.net/
[1] https://static.simonwillison.net/static/2025/qwen3-coder-plu...
I wanted to start using the Alibaba cloud for a personal project six months ago, couldn't make sense of the pricing and just gave up, so it's not new in my humble experience...
I have 4x3090 (96GB) and 128GB DDR4 RAM, can I run unsloth on this machine and utilize all 4 GPUs?
Wow, these companies in the llm field is so quick to catch up. From everyone offering their own chat model to openai-compitable schema to allowing extensions and IDEs do the work to agentic tasks and now most of them offering their own cli
Thank god I already made an Alibaba Cloud account last year because this interface sucks big time. At least you get 1 mio. tokens free (once?). Bit confusing that they forked the Gemini CLI but you still have to set environment variables for OpenAI?
At this point the openai compatible API is the de facto standard. You probably want to set both the base_url and api key, so you can test with 3rd party providers.
So far none of these models can write even a slightly complicated function well for me. I tried Mistral, ChatGPT, Qwen Coder 2, Claude, ... they apparently all fail when the solution requires to make use of continuations and such. Probably, because they don't have enough examples in their training data or something.
Example: Partition a linked list in linear time. None of these models seems to be able to get, that `reverse` or converting the whole list to a vector are in themselves linear operations and therefore forbid themselves. When you tell them to not use those, they still continue to do so and blatantly claim, that they are not using them. Á la:
"You are right, ... . The following code avoids using `reverse`, ... :
[code that still uses reverse]"
And in languages like Python they will cheat, because Python's list is more like an array, where random access is O(1).
This means they only work well, when you are doing something quite mainstream, where the amount of training data is a significantly strong signal in the noise. But even there they often struggle. For example I found them somewhat useful for doing Django things, but just as often they gave bullshit code, or it took a lot of back and forth to get something useful out of them.
I think it is embarrassing, that with sooo much training data, they are still unable to do much more than going by frequency in training data when suggesting "solutions". They are "learning" differently than a human being. When a human being sees a new concept, they can often apply that new concept, even if that concept does not happen to be needed that often, as long as they remember the concept. But in these LLMs it seems they deem everything that isn't mainstream irrelevant.
I just asked Gemini 2.5 Pro to write a function in Haskell to partition a list in linear time, and it did it perfectly. When you say you were using ChatGPT and Claude, do you mean you were using the free ones? Plain GPT 4o is very poor at coding.
-- | Takes a predicate and a list, and returns a pair of lists. -- | The first list contains elements that satisfy the predicate. -- | The second contains the rest. partitionRecursive :: (a -> Bool) -> [a] -> ([a], [a]) partitionRecursive _ [] = ([], []) -- Base case: An empty list results in two empty lists. partitionRecursive p (x:xs) = -- Recursively partition the rest of the list let (trues, falses) = partitionRecursive p xs in if p x -- If the predicate is true for x, add it to the 'trues' list. then (x : trues, falses) -- Otherwise, add it to the 'falses' list. else (trues, x : falses)My Haskell reading is weak, but that looks like it would change the order of elements in the 2 lists, as you are prepending items to the front of `trues` and `falses`, instead of "appending" them. Of course `append` is forbidden, because it is linear runtime itself.
I just checked my code and while I think the partition example still shows the problem, the problem I used to check is a similar one, but different one:
Split a list at an element that satisfies a predicate. Here is some code for that in Scheme:
For this kind of stuff with constructed continuations they somehow never get it. They will do `reverse` and `list->vector`, and `append` all day long or some other attempt of working around what you specify they shall not do. The concept of building up a continuation seems completely unknown to them.(define split-at (λ (lst pred) "Each element of LST is checked using the predicate. If the predicate is satisfied for an element, then that element will be seen as the separator. Return 2 values: The split off part and the remaining part of the list LST." (let iter ([lst° lst] [index° 0] [cont (λ (acc-split-off rem-lst) (values acc-split-off rem-lst))]) (cond [(null? lst°) (cont '() lst°)] [(pred (car lst°) index°) (cont '() (cdr lst°))] [else (iter (cdr lst°) (+ index° 1) (λ (new-tail rem-lst) (cont (cons (car lst°) new-tail) rem-lst)))]))))
> [code that still uses reverse]
I get this kind of lying from Gemini 2.5 Flash sometimes. It's super frustrating and dissolves all the wonder that accumulated when the LLM was giving useful responses. When it happens, I abandon the session and either figure out the problem myself or try a fresh session with more detailed prompting.
I use it more like documentation, I know it can't really invent things for me.
Can someone please make these CLI from Rust/Ratatui.
I made one using Rust predating Gemini-CLI https://github.com/MostlyKIGuess/Yappus-Term , but it's more of a search tool than coding.
Closest you get is https://github.com/opencode-ai/opencode in GO.
OpenAI's Codex has a Rust and Ratatui implementation. I believe it's now the default verison. (Previously the TypeScript implementation was the default.)
Amazon's Claude Code clone is in Rust and Apache-2/MIT:
I'm waiting on this to be released on Groq or Cerebras for high speed vibe coding.
I was only getting like 200 tk/s with groq on K2, was expecting it to be faster tbh.
I think the bottleneck is file read/write tooling right now
I checked this website along with API pricing on OpenRouter, and this one beats Gemini 2.5 Pro (…Preview-0506 in their chart, but with a good margin so probably the non-preview too) at half Google’s API price. Nice. Admittedly their own posted benchmark, but still. If it even just competes with it, it’s a win.
Edit:
I ran my fun test on it and it unfortunately failed.
> ”How can I detect whether a user is running in a RemoteApp context using C# and .NET? That is, not a full RDP desktop session, but a published RemoteApp as if the app is running locally. The reason I’m asking is that we have an unfortunate bug in a third party library that only shows up in this scenario, and needs a specific workaround when it happens.”
It started by trying to read hallucinated environment variables that just aren’t there. Gemini 2.5 Pro had the same issue and IIRC also Claude.
The only one I have seen give the correct answer that is basically ”You can’t. There’s no official method to do this and this is intentional by Microsoft.” along with a heuristic to instead determine the root launching process which is thus far (but not guaranteed to be) RDPINIT.EXE rather than EXPLORER.EXE as in typical desktop or RDP scenarios… has been OpenAI o3. o3 also provided additional details about the underlying protocol at play here which I could confirm with external sources to be correct.
I like my query because it forces the LLM to actually reply with that you just can’t do this, there’s no ”sign” of it other than going by a completely different side-effect. They are usually too eager to try to figure out a positive reply and hallucinate in the process. Often, there _are_ these env vars to read in cases like these, but not here.
I'm confused why would this LLM require API keys to openAI?
The env variables names are misleading. They don't require api keys to OpenAI. Apparently, their tool can connect to any open ai compatible api and that's how you configure your crendentials. You can point it to openrouter or nebius.com to use other models.
Now I await the distilled options.
I wonder if there's a python expert that can be isolated.
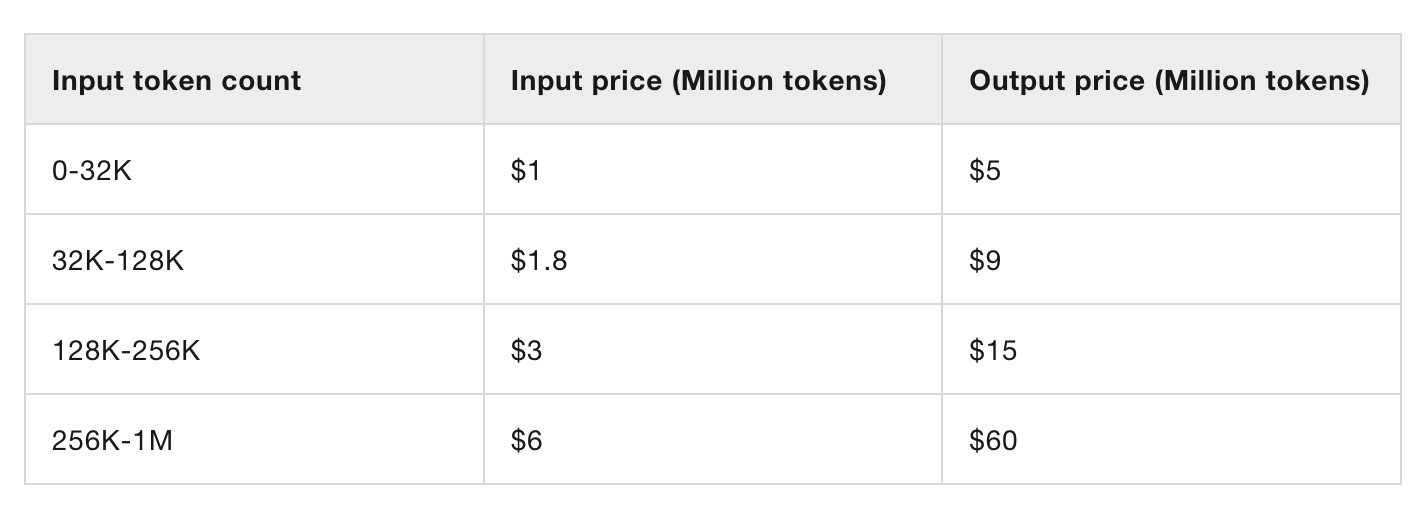{kind=link}