They trained it in 33 days for ~20m (that includes apparently not only the infrastructure but also the salaries over a 6 month period). And the model is coming close to QWEN and Deepseek. Pretty impressive
The price/scaling of training another same class model always seems to be dropping through the floor but training models which score much better seems to be hitting a brick wall.
E.g. gemini-3-pro tops the lmarena text chart today at 1488 vs 1346 for gpt-4o-2024-05-13. That's a win rate of 70% (where 50% is equal chance of winning) over 1.5 years. Meanwhile, even the open weights stuff OpenAI gave away last summer scores between the two.
The exception seems to be net new benchmarks/benchmark versions. These start out low and then either quickly get saturated or hit a similar wall after a while.
> E.g. gemini-3-pro tops the lmarena text chart today at 1488 vs 1346 for gpt-4o-2024-05-13. That's a win rate of 70% (where 50% is equal chance of winning) over 1.5 years. Meanwhile, even the open weights stuff OpenAI gave away last summer scores between the two.
Why do you care about LM Arena? It has so many problems, and the fact that no one would suggest using GPT-4o for doing math or coding right now, or much of anything, should tell you that a 'win rate of 70%' does not mean whatever it looks like it means. (Does GPT-4o solve roughly as many Erdos questions as gemini-3-pro...? Can you write roughly as good poetry?)
It'd certainly be odd if people were recommending old LLMs which score worse, even if marginally. That said, 4o is really a lot more usable than you're making it out to be.
The particular benchmark in the example is fungible but you have to pick something to make a representative example. No matter which you pick someone always has a reason "oh, it's not THAT benchmark you should look at". The benchmarks from the charts in the post exhibit the same as described above.
If someone was making new LLMs which were consistently solving Erdos problems at rapidly increasing rates then they'd be showing how it does that rather than showing how it scores the same or slightly better on benchmarks. Instead the progress is more like years since we were surprised LLMs were writing poetry to massage out an answer to one once. Maybe by the end of the year a few. The progress has definitely become very linear and relatively flat compared to roughly the initial 4o release. I'm just hoping that's a temporary thing rather than a sign it'll get even flatter.
Frankly, this reads as a lot of words that amount to an excuse for using only LMArena, and the rationale is quite clear: it’s for an unrelated argument that isn’t going to ring true to people, especially an audience of programmers who just spent the last year watching the AI go from being able to make coherent file edits to multi hour work.
LMArena is, de facto, a sycophancy and Markdown usage detector.
Two others you can trust, off the top of my head, are LiveBench.ai and Artifical Analysis. Or even Humanity’s Last Exam results. (Though, frankly, I’m a bit suspicious of them. Can’t put my finger on why. Just was a rather rapid hill climb for a private benchmark over the last year.)
FWIW GPT 5.2 unofficial marketing includes the Erdos thing you say isn’t happening.
I've always found LiveBench a bit confusing to try to compare over time as the dataset isn't meant to be compared over time. It also currently claims GPT-5 Mini High from last summer is within ~15% of Claude 4.5 Opus Thinking High Effort in the average, but I'll wait with bated breath for the millions of amazing apps which couldn't be coded before to start showing up (or, more likely, be told in 6 months how these 2 benchmarks weren't the ones that should matter either). Artificial Analysis at least has the same at 20% from the top, so maybe that's the one we all agree to use for now since it implies faster growth.
> FWIW GPT 5.2 unofficial marketing includes the Erdos thing you say isn’t happening.
Certainly not, unless you're about to tell me I can pop into ChatGPT and pop out Erdos proofs regularly since #728 was massaged out with multiple prompts and external tooling a few weeks ago - which is what I was writing about. It was great, it was exciting, but it's exactly the slow growth I'm talking about.
I like using LLMs, I use them regularly, and I'm hoping they continue to get better for a long time... but this is in no way the GPT 3 -> 3.5 -> 4 era of mind boggling growth of frontier models anymore. At best, people are finding out how to attach various tooling to the models to eek more out as the models themselves very slowly improve.
They didn't do something stupid like Llama 4 "one active expert", but 4 of 256 is very sparse. It's not going to get close to Deepseek or GLM level performance unless they trained on the benchmarks.
I don't think that was a good move. No other models do this.
There's a free preview on openrouter: https://openrouter.ai/arcee-ai/trinity-large-preview:free
It's super exciting to see another American lab get in the ring. Even if they're not at SOTA on the first release, the fact that they're trying is incredible for open source AI.
I'm particularly excited to see a "true base" model to do research off of (https://huggingface.co/arcee-ai/Trinity-Large-TrueBase).
What did they do to make the loss drop so much in phase 3?
Also, why are they comparing with Llama 4 Maverick? Wasn’t it a flop?
```During development of the RSDB, we noted significant enough performance gains from it that we decided to integrate it during phase 3 of the Trinity Large training run instead of waiting for a later training run. While the data distributions between phase 2 and phase 3 make direct comparison difficult, the overall effect was notable: BatchHet reduced by a factor of 4.23x, and step-to-step variance reduced by a factor of 2.4x (see Figure 1), a significant improvement when compared to the default packing strategy. We note that training runs without the RSDB exhibit much higher values in the higher-order moments of the running loss distribution, which we believe to correlate with network instability during training. ```
Page 9 of the technical report has more details, but it looks like they found some data prep methods as well as some other optimizations that overall worked out really well. I don't think it was any one particular thing.
As far as Llama 4 goes, it was only referenced as a similarly sized model, they called it one of their model "peers"; I don't think they intended any sort of quality comparison. Llama 4 was notable for sparsity, despite its poor performance and reception, some of the things they achieved technically were solid, useful research.
you can’t directly compare losses because they changed the data distribution for each phase ( I think. 100% guaranteed they change the data distribution after the 10 trillion token mark, that’s when they start adding in instruction following data, but I don’t know for sure if the other phase changes also include data distribution changes.)
Given that it's a 400B-parameter model, but it's a sparse MoE model with 13B active parameters per token, would it run well on an NVIDIA DGX Spark with 128 GB of unified RAM, or do you practically need to hold the full model in RAM even with sparse MoE?
Even with MoE, holding the model in RAM while individual experts are evaluated in VRAM is a bit of a compromise. Experts can be swapped in and out of VRAM for each token. So RAM <-> VRAM bandwidth becomes important. With a model larger than RAM, that bandwidth bottleneck gets pushed to the SSD interface. At least it's read-only, and not read-write, but even the fastest of SSDs will be significantly slower than RAM.
That said, there are folks out there doing it. https://github.com/lyogavin/airllm is one example.
Can run with mmap() but it is slower. 4-bit quantized there is a decent ratio between the model size and the RAM, with a fast SSD one could try to see how it works. However when a model is 4-bit quantized there is often the doubt that it is not better than an 8-bit quantized model of 200B parameters, it depends on the model, on the use case, ... Unfortunately the street for local inference of SOTA model is being stopped by the RAM prices and the GPU request of the companies, leaving us with little. Probably today the best bet is to buy Mac Studio systems and then run distributed inference (MLX supports this for instance), or a 512 GB Mac Studio M4 that costs, like 13k$.
Talking about RAM prices, you can still get a framework Max+ 395 with 128GB RAM for ~$2,459 USD. They have not increased the price for it yet.
https://frame.work/products/desktop-diy-amd-aimax300/configu...
Pretty sure those use to be $1999 ... but not entirely sure
Yep. You be right. Looks like they increased it earlier this month. Bummer!
No.
128GB vram gets you enough space for 256B sized models. But 400B is too big for the DGX Spark, unless you connect 2 of them together and use tensor parallel.
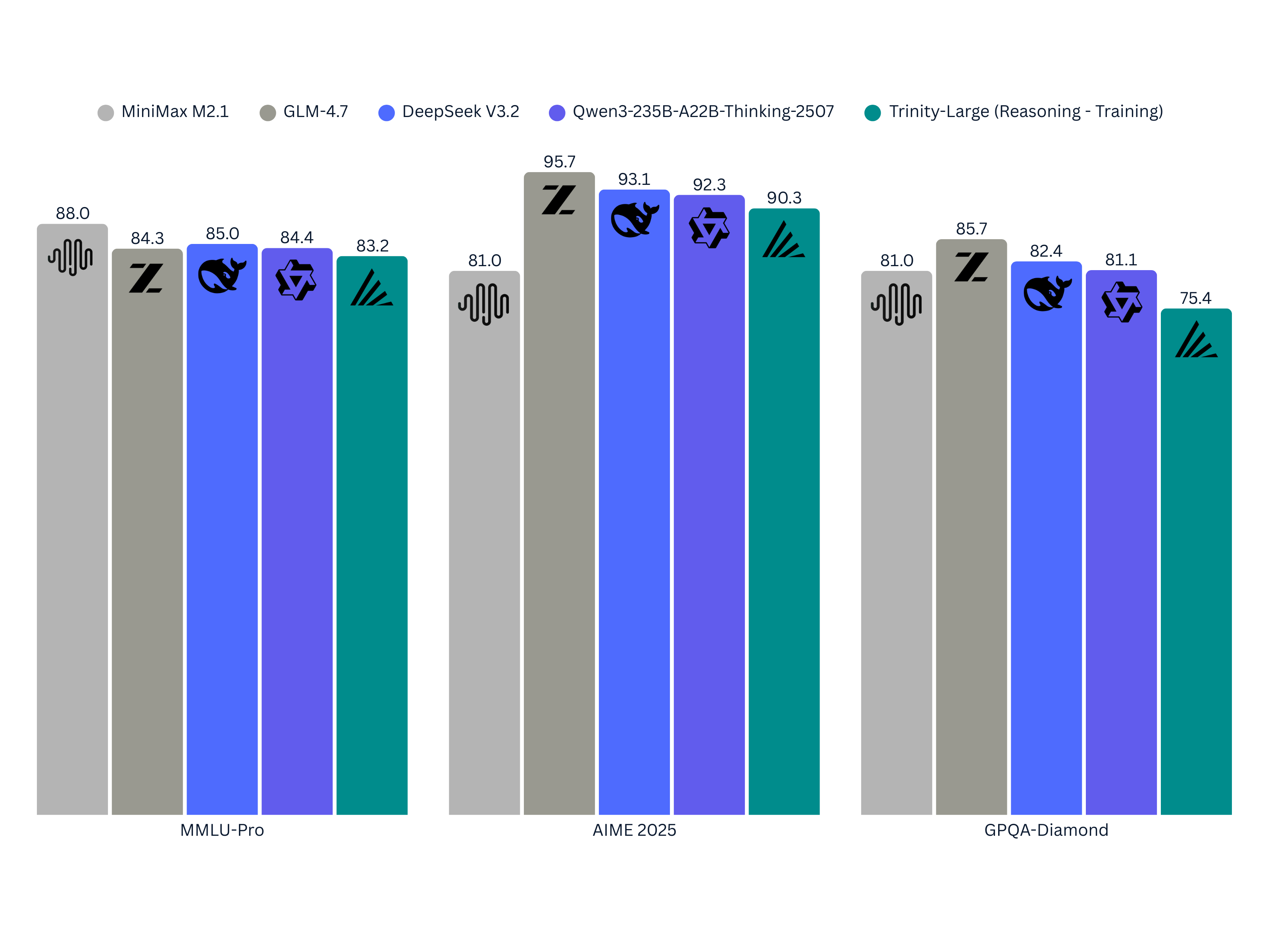
The only thing I question is the use of Maverick in their comparison charts. That's like comparing a pile of rocks to an LLM.
It's because they're doing 4 of 256 sparsity, which was a bad decision caused by financial limitations.
Training cost (FLOPs) = 6 * active params * total tokens. By keeping the MoE experts param count low, it reduces total training costs.
I don't think this was a good move. They should have just trained way past chinchilla like the other major labs, and keep sparsity above 2%. Even Kimi K2 is above 2%. GLM is at 5%, which makes it very expensive (and high performing) for its small size.
Arcee went the other way. They trained a massive 400b model (bigger than GLM-4.5/4.6/4.7, bigger than Qwen3 235b A23b), but only have 17b active params, which is smaller than Qwen and GLM. It's also only trained on 17T tokens, vs 20-30T+ tokens for the other models. It's just undertrained and undersized (in terms of active parameters), and they got much worse performance than those models:
https://45777467.fs1.hubspotusercontent-na1.net/hubfs/457774...
It's not a bad showing considering the limitations they were working with, but yeah they definitely need double the active experts (8 out of 256 instead of 4 out of 256) to be competitive. That would roughly double the compute cost for them, though.
Their market strategy right now is to have less active params so it's cheaper for inference, more total params so it's smarter for the amount of active params they have, but not too big to fit into a H200 cluster. I... guess this is a valid niche strategy? The target audience is basically "people who don't need all the intelligence of GLM/Qwen/Deepseek, but want to serve more customers on the H200 cluster they already have sitting around". It's a valid niche, but a pretty small one.
There aren't too many base models out there to compare against.
What exactly does "open" mean in this case? Is it weights and data or just weights?
It's always open weights.
It's never open data
Well, it is, it's your data to begin with after all but admitting that would create some problems.
This model is sort of interesting since it seems to be using a lot of synthetic training data – but your point stands
So it's a rip off of a rip off, is that whats interesting?
> We optimize for performance per parameter and release weights under Apache-2.0
How do they plan to monetize?
unsloth quants are up https://huggingface.co/unsloth/Trinity-Large-Preview-GGUF
So refreshing to see open source models like this come from the US. I would love for a 100Bish size one that can compete against OSS-120B and GLM air 4.5
According to the article, nearly 50% of the dataset is synthetic (8T out of 17T tokens). I don't know what constitutes "a breadth of state-of-the-art rephrasing approaches", but I lack some confidence in models trained on LLM output, so I hope it wasn't that.
This is a wonderful release.
Is anyone excited to do ablative testing on it?
With such a high throughput because of sparsity, I'm particulary interested in distilling it into other architectures. I'd like to try a recurrent transformer when I have the time
{kind=link}